Automatiser la recherche immobilière : retour d’expérience sur la conception d’un système de veille intelligent
🏡 Chercher un logement aujourd’hui est devenu un vrai second job. Rafraîchir Leboncoin, Bien’ici, PAP des dizaines de fois par jour… Trier, filtrer, éliminer les annonces hors sujet… Et malgré ça, passer à côté des meilleures opportunités. J’ai été confronté exactement à ce problème. Plutôt que d’y passer des heures chaque jour, j’ai conçu un système qui travaille pour moi 24h/24. 👉 L’idée : automatiser entièrement la veille immobilière, avec un filtrage réellement intelligent. Concrètement, le système : - surveille plusieurs plateformes en continu - applique plusieurs niveaux de filtrage (règles + IA) - ne remonte que les annonces réellement pertinentes Chaque annonce est analysée et scorée, ce qui permet d’éviter le bruit et de se concentrer uniquement sur ce qui vaut le coup. 🎯 Dès les premières utilisations, j’ai pu identifier rapidement plusieurs biens pertinents, là où une recherche classique m’aurait demandé plusieurs heures de tri. Ce que ça change concrètement : - moins de temps perdu - moins de fatigue mentale - et surtout, moins d’opportunités manquées ⚙️ Derrière, ce n’est pas “juste un script”, mais une vraie logique de système : - scraping multi-sources - filtrage multi-niveaux - scoring via LLM - orchestration automatisée Là où les choses deviennent vraiment intéressantes, c’est sur les critères qualitatifs. Les filtres classiques permettent de définir un budget, une surface ou un nombre de pièces. Mais ils deviennent rapidement insuffisants dès qu’on sort du cadre strictement structuré. L’idée étant d’ajouter aux paramètres standard des critères qui font la différence : 💡 “Dans l’idéal, j’aimerais un jardin orienté plein sud, la maison doit avoir du charme ainsi que le jardin, pas de vis-à-vis à l’extérieur, avec un parking couvert, je voudrais aussi un chauffage au sol.” Ces critères ne sont pas bloquants : ils viennent enrichir l’analyse et influencer le scoring global, en permettant de faire remonter les biens qui correspondent le mieux aux préférences exprimées. C’est précisément là que l’IA apporte de la valeur : 👉 interpréter des contraintes “humaines” et nuancées, et les intégrer dans une évaluation de pertinence. Dans la suite, je détaille l’architecture, les choix techniques et les limites rencontrées.
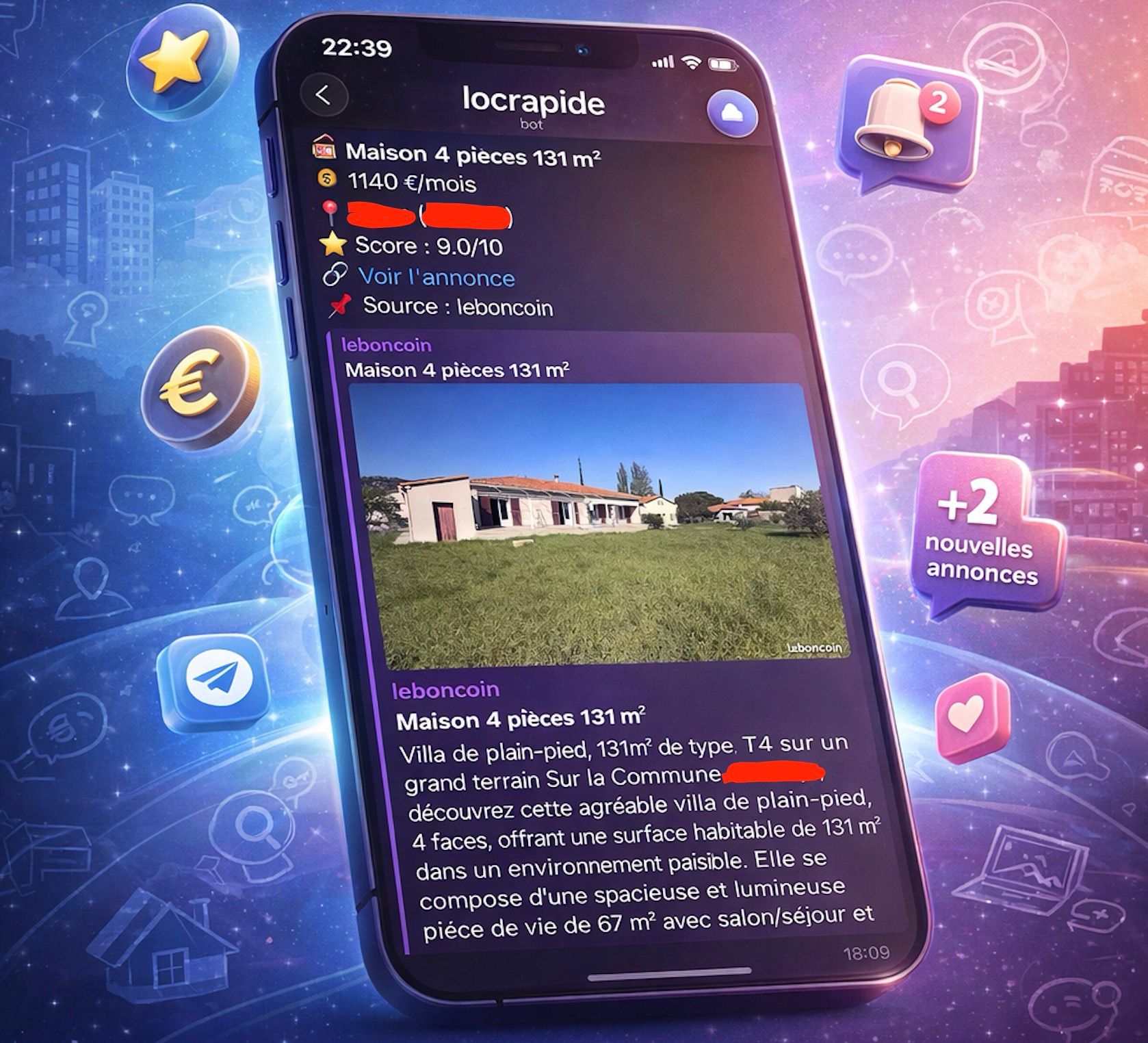 Le problème que tout chercheur de logement connaît
Le problème que tout chercheur de logement connaît
Quiconque a déjà cherché un logement, à la location comme à l’achat, connaît cette routine rapidement chronophage : ouvrir Leboncoin, configurer la recherche, actualiser, scroller, passer à Bien'ici, recommencer, puis PAP… et répéter ce cycle plusieurs fois par jour pendant des semaines.
Les bonnes annonces partent souvent en quelques heures. Dans le même temps, les filtres proposés par les plateformes restent relativement limités : difficile, par exemple, d’exprimer des contraintes précises comme “jardin attenant d’au moins 250 m²” ou “exclure toute forme de colocation déguisée", "je cherche un jardin avec des palmiers", "je veux une salle de bain avec douche à l'italienne”.
Résultat : beaucoup de bruit, beaucoup de temps perdu, et des opportunités manquées.
Execution :
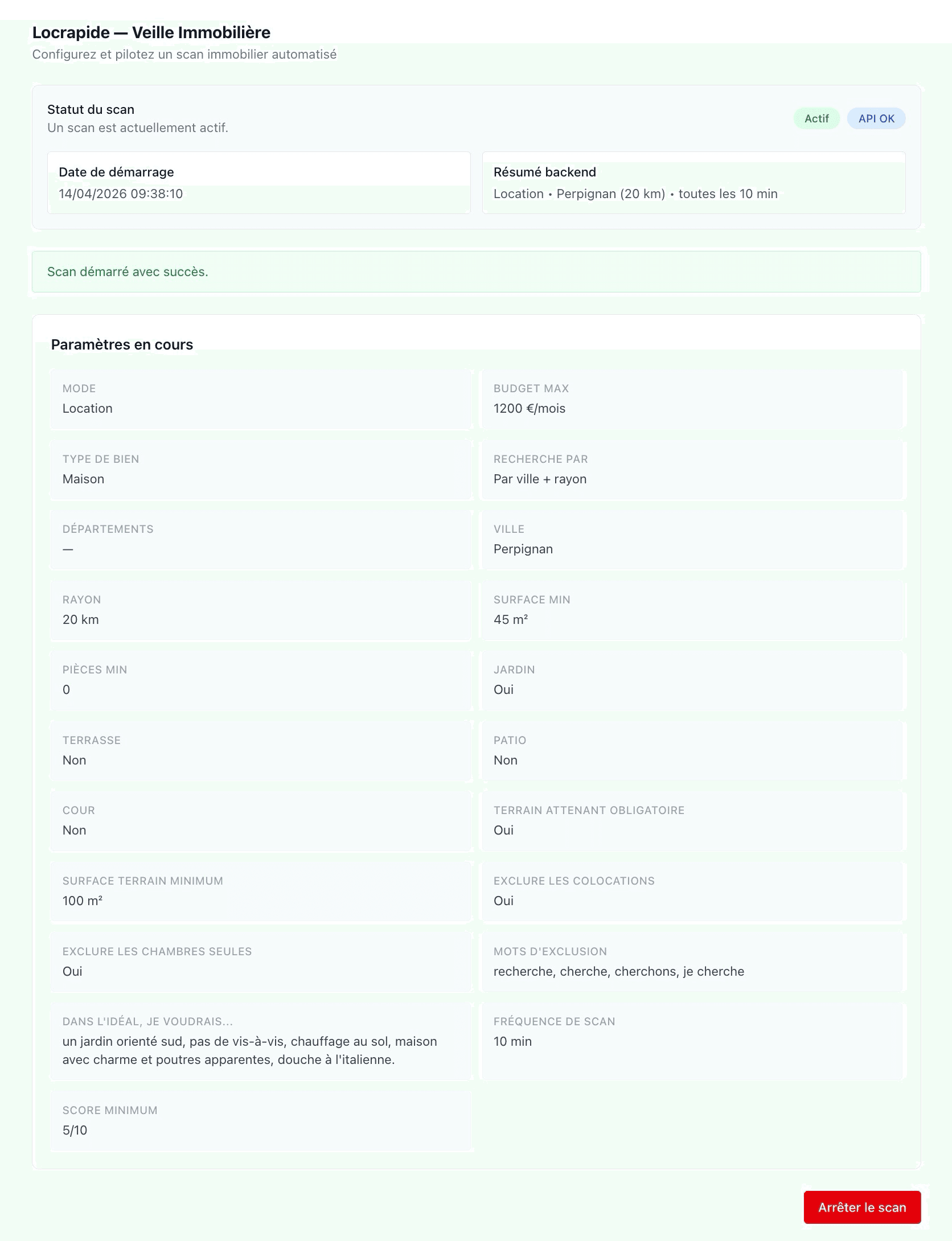
Concevoir un système pour automatiser la veille
Plutôt que d’optimiser marginalement cette recherche, j’ai choisi de changer d’approche : concevoir un système capable de la prendre en charge de manière autonome.
L’objectif n’était pas simplement d’agréger des annonces, mais de reproduire — et systématiser — un processus de sélection pertinent :
- surveiller plusieurs sources en continu
- filtrer rapidement ce qui est hors sujet
- analyser finement le contenu restant
- ne remonter que les annonces réellement intéressantes
Architecture générale
Le système repose sur un pipeline relativement simple dans sa logique, mais structuré pour être robuste et extensible :
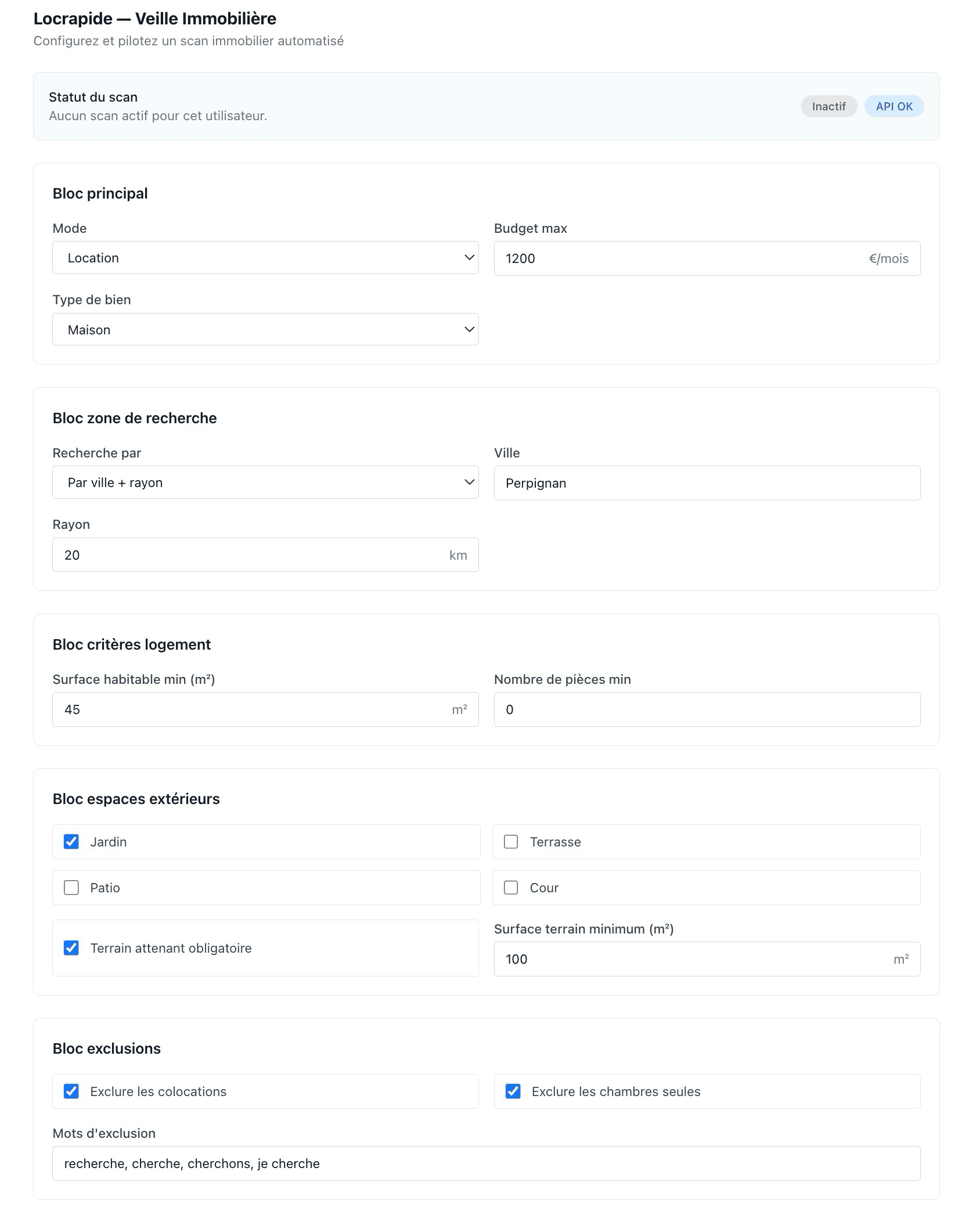
- Configuration des critères via une interface dédiée
- Surveillance continue de plusieurs sources
- Filtrage en plusieurs étapes
- Scoring intelligent des annonces
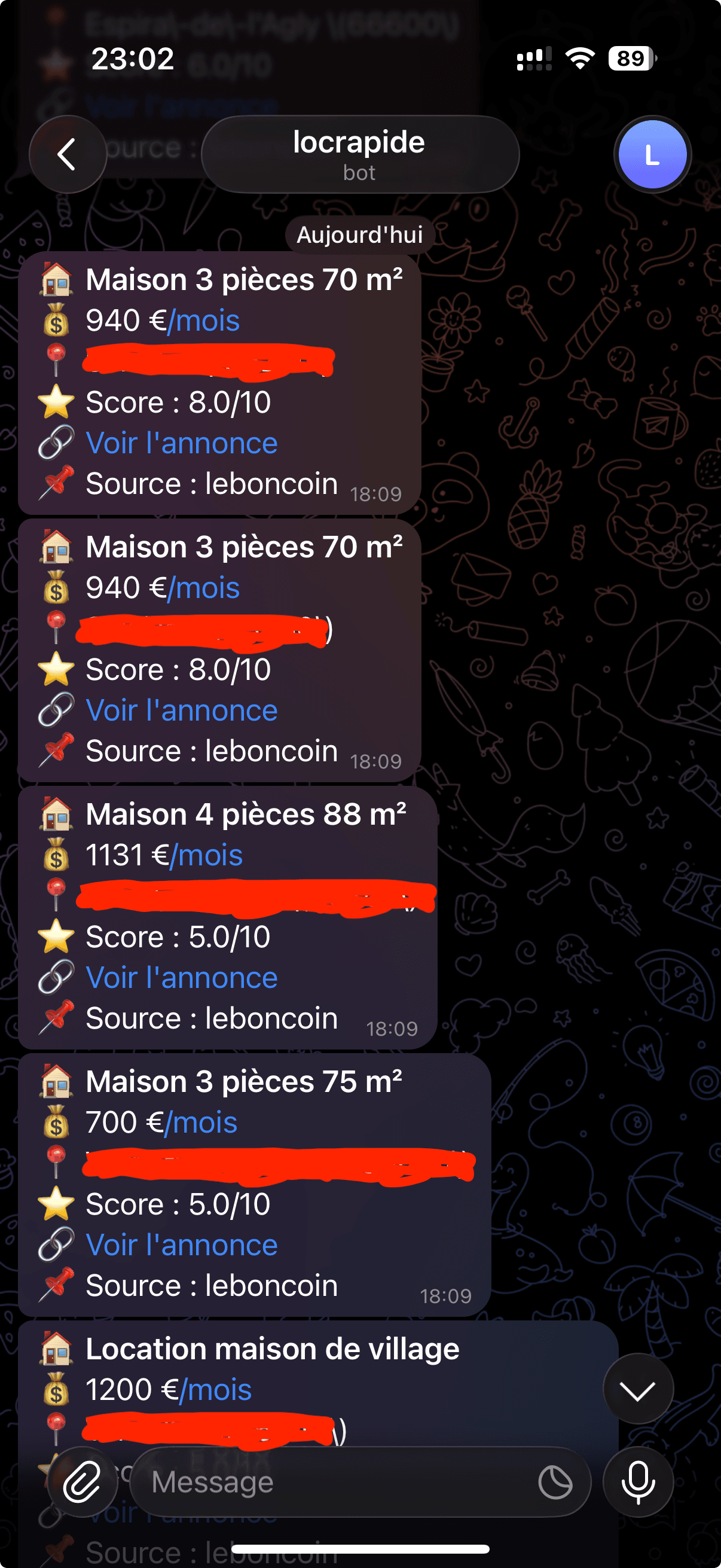
- Notification des résultats pertinents
Un filtrage en plusieurs niveaux
L’un des points clés est d’éviter de solliciter inutilement les modèles d’IA, tout en conservant un bon niveau de précision.
Pour cela, le traitement est découpé en trois étapes.
1. Pré-filtrage
Une première passe élimine immédiatement :
- les annonces vides ou incomplètes
- les “recherches de logement”
- les contenus contenant des mots interdits
- les biens hors zone géographique
Ce niveau permet de réduire fortement le volume à traiter.
2. Filtrage déterministe
Une seconde étape applique des règles simples :
- prix
- surface
- nombre de pièces
Ce filtrage mécanique permet d’écarter rapidement les cas non pertinents sans coût supplémentaire.
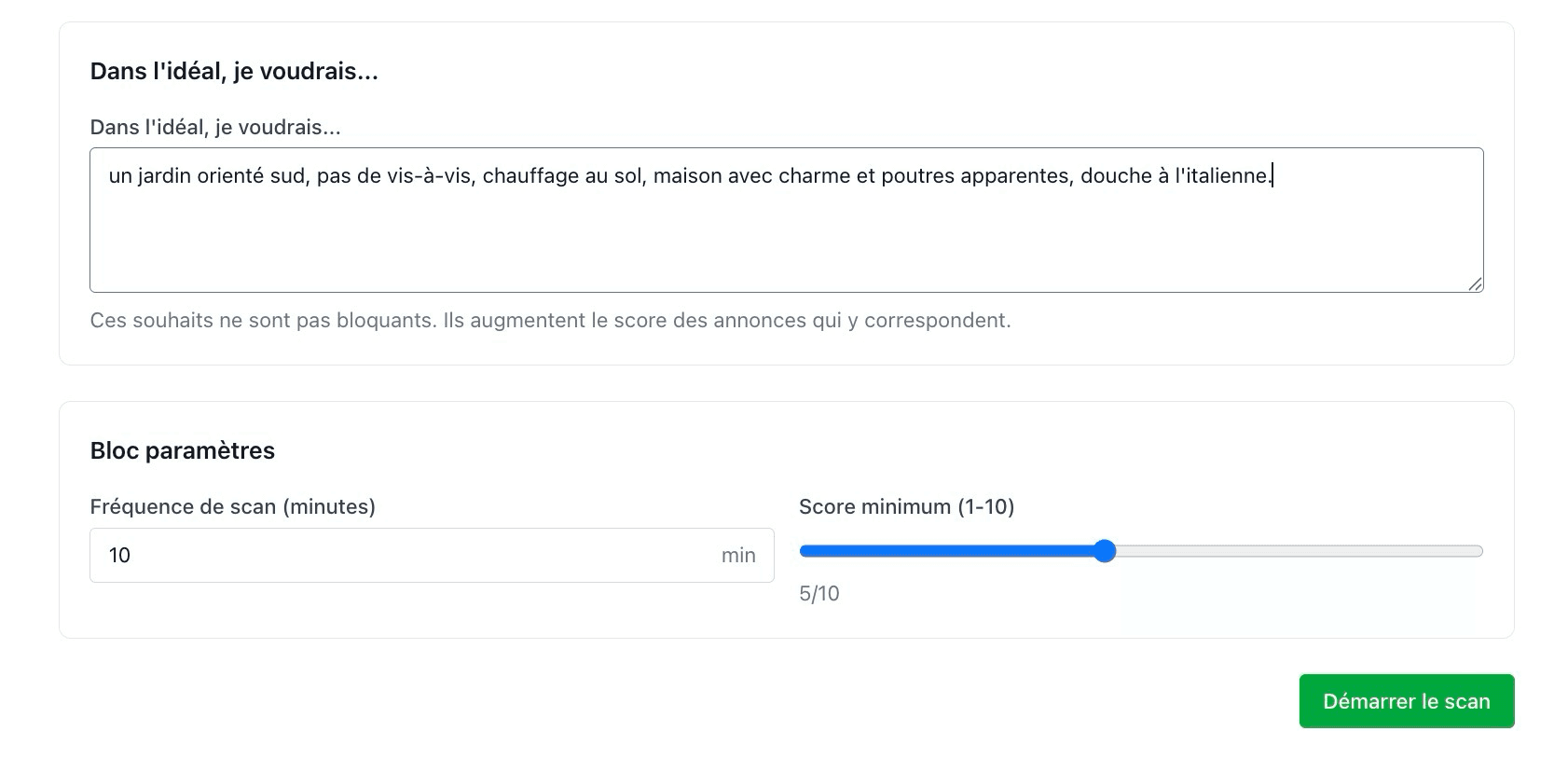
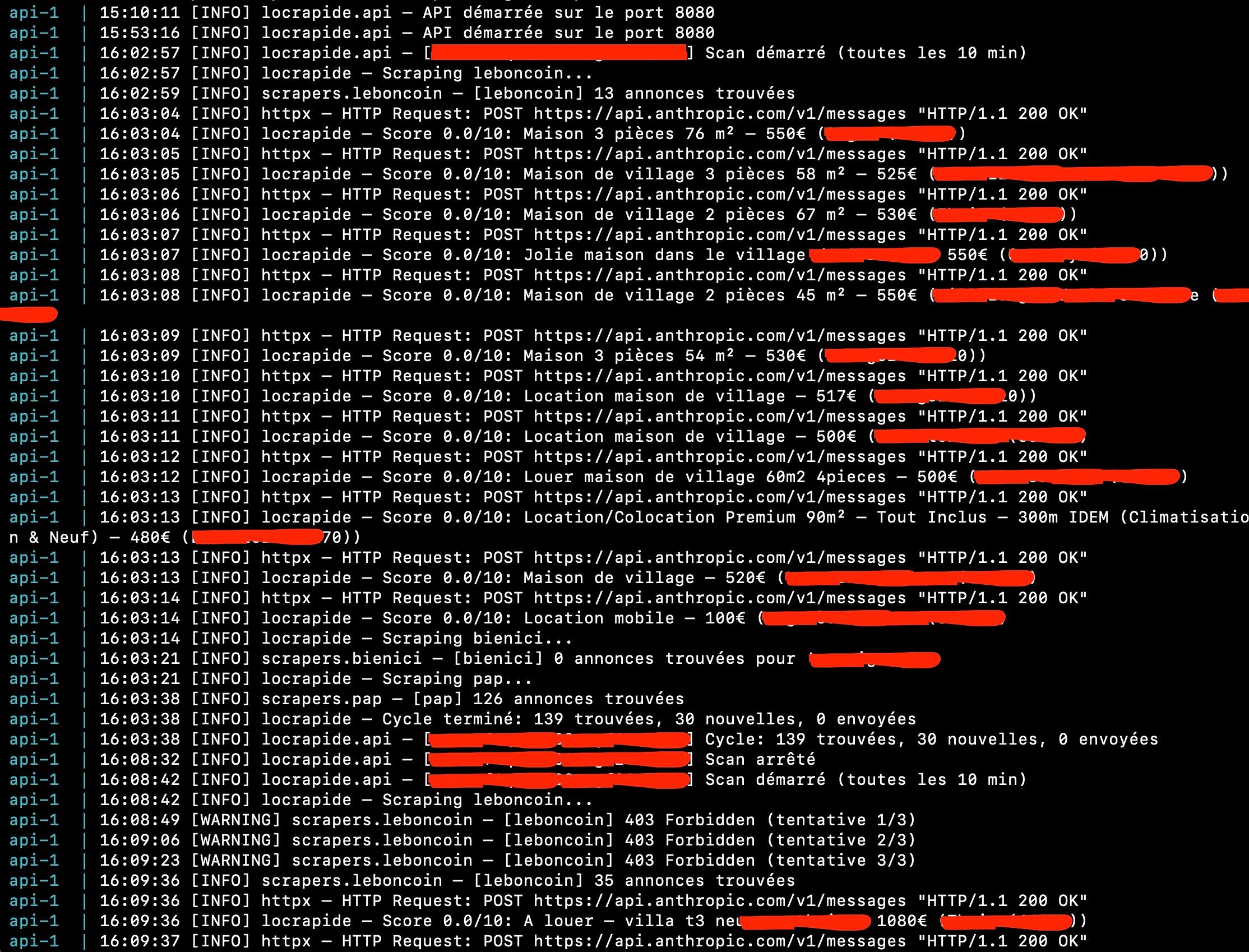
3. Scoring via modèle de langage
Le cœur du système repose sur l’utilisation d’un LLM (ici Anthropic via le modèle Claude Haiku).
Chaque annonce restante est analysée à partir d’un prompt généré dynamiquement en fonction des critères utilisateur.
Le modèle attribue un score de pertinence de 0 à 10, permettant de hiérarchiser les résultats.
Un point important : le prompt n’est pas statique. Il est construit automatiquement à partir des contraintes définies, ce qui permet d’adapter finement l’analyse à chaque cas.
Collecte des données
Le système s’appuie sur plusieurs sources immobilières, chacune avec des modes d’accès et des contraintes techniques spécifiques.
Certaines plateformes exposent encore des endpoints JSON relativement exploitables avec des paramètres structurés, tandis que d’autres reposent sur des interfaces fortement protégées, avec des mécanismes de détection d’automatisation de plus en plus avancés.
Dans la pratique, cela se traduit par différents cas de figure :
- accès via API interne avec validation des paramètres de requête
- pages HTML nécessitant une interprétation côté navigateur
- protections anti-bot reposant sur la détection d’IP, l’analyse comportementale ou l’exécution de JavaScript
👉 Tous ces éléments rendent la collecte de données non triviale, et surtout évolutive dans le temps.
Gestion des contraintes anti-automatisation
Les plateformes immobilières utilisent aujourd’hui des solutions spécialisées pour limiter les accès automatisés (WAF, challenges JavaScript, détection d’IP de datacenter, etc.).
Ces mécanismes introduisent des contraintes fortes :
- un comportement acceptable depuis une IP résidentielle peut être bloqué depuis une infrastructure serveur
- certaines pages nécessitent l’exécution de JavaScript pour être accessibles
- des endpoints peuvent être modifiés, restreints ou supprimés sans préavis
Stratégies d’adaptation
Pour garantir la robustesse du système, plusieurs approches sont envisagées selon les sources :
- utilisation de proxys adaptés pour rapprocher le trafic d’un usage réel
- recours à des navigateurs headless pour reproduire fidèlement le comportement d’un navigateur
- adaptation dynamique des patterns de requêtes et des fréquences d’appel
Chaque solution implique des arbitrages entre :
- performance
- coût
- complexité
- maintenabilité
Gestion des doublons et architecture
Chaque utilisateur dispose de sa propre base SQLite, ce qui permet de garantir qu’une annonce ne soit jamais envoyée deux fois.
L’ensemble est déployé dans une architecture simple mais cloisonnée :
- backend Python exposé via API REST
- exécution dans un conteneur Docker
- hébergement sur une LXC Proxmox
- interface de configuration isolée en DMZ
Stack utilisée : Python 3.12, LLM (Claude Haiku), Telegram Bot, SQLite, Docker, Proxmox, VyOS.
Enseignements
Après les premières itérations, plusieurs points se dégagent.
- Le scoring via LLM est très efficace, mais extrêmement dépendant de la qualité du prompt. Le calibrage est un sujet en soi.
- Introduire une “zone grise” (scores intermédiaires) permet de ne pas rater des opportunités lorsque les descriptions sont incomplètes.
- Générer dynamiquement les prompts à partir d’une interface utilisateur simplifie fortement l’usage tout en conservant de la précision.
- La modularité des scrapers est essentielle : les sources évoluent régulièrement, et chaque connecteur doit pouvoir être adapté indépendamment, notamment face aux mécanismes de protection anti-automatisation qui évoluent en permanence.
Un pattern applicable à d’autres cas
Au-delà du cas immobilier, ce type d’architecture correspond à un schéma plus général :
👉 veille multi-sources + filtrage progressif + scoring intelligent
Ce pattern peut s’appliquer à de nombreux contextes :
- veille concurrentielle
- sourcing de leads
- détection d’opportunités (marché, recrutement, data…)
- tri automatisé de contenus à forte volumétrie
Ouverture
Ce projet est avant tout un cas concret d’application de l’automatisation et des modèles de langage à un problème réel.
Il illustre surtout une approche : structurer un flux de données, réduire le bruit progressivement, et n’appliquer l’intelligence que là où elle apporte réellement de la valeur.
💬 Si vous travaillez sur des problématiques similaires (veille, filtrage, automatisation, IA), ou que vous avez besoin de concevoir ce type de système sur mesure, je serai ravi d’échanger.