Concevoir une architecture cloud réellement résiliente : ce que font (vraiment) les entreprises matures sur AWS
Aujourd’hui, beaucoup d’entreprises pensent être “cloud-ready”. En réalité, une grande partie des architectures que je vois reposent encore sur des compromis : dépendance à une seule zone sécurité approximative absence de stratégie de reprise après incident déploiements risqués 👉 Le problème n’est pas la technologie. 👉 Le problème, c’est le niveau d’exigence dans la conception. J’ai donc conçu une architecture AWS complète, inspirée des standards des grands comptes, pour répondre à une question simple : À quoi ressemble une plateforme microservices vraiment robuste, sécurisée et scalable en production ? Dans cet article, je vulgarise les grands principes sans jargon inutile. Maintenant passons à la partie technique détaillée :
🎯 Pourquoi ce projet ?
Dans les environnements critiques (SaaS, finance, industrie…), une architecture cloud ne doit pas seulement “fonctionner”.
Elle doit être capable de :
- encaisser des pics de charge
- résister à des pannes
- sécuriser les données
- évoluer sans interruption
- être observable et pilotable
C’est exactement ce que j’ai modélisé ici : une architecture microservices haute disponibilité sur AWS, basée sur les bonnes pratiques des environnements entreprise.
🏗️ 1. Une architecture pensée pour ne jamais tomber
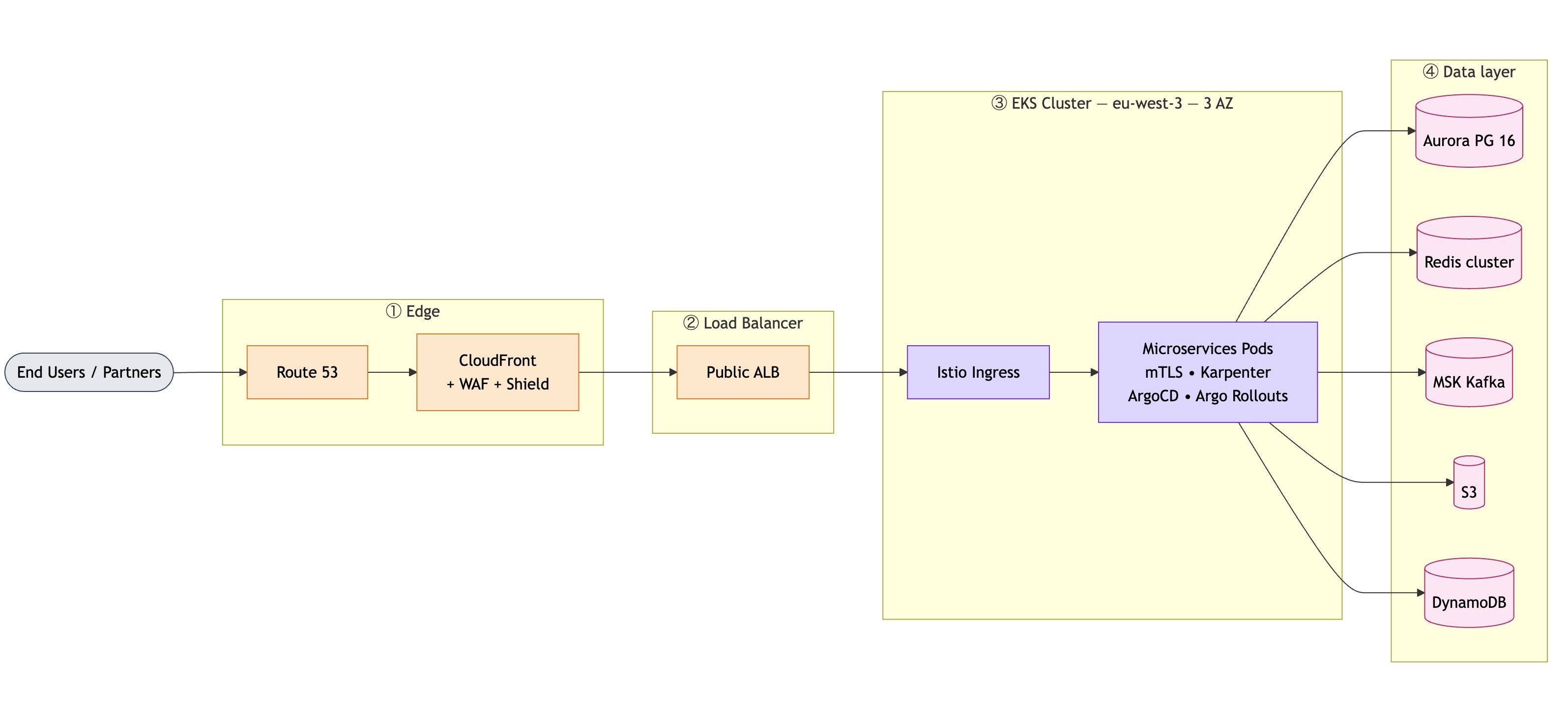
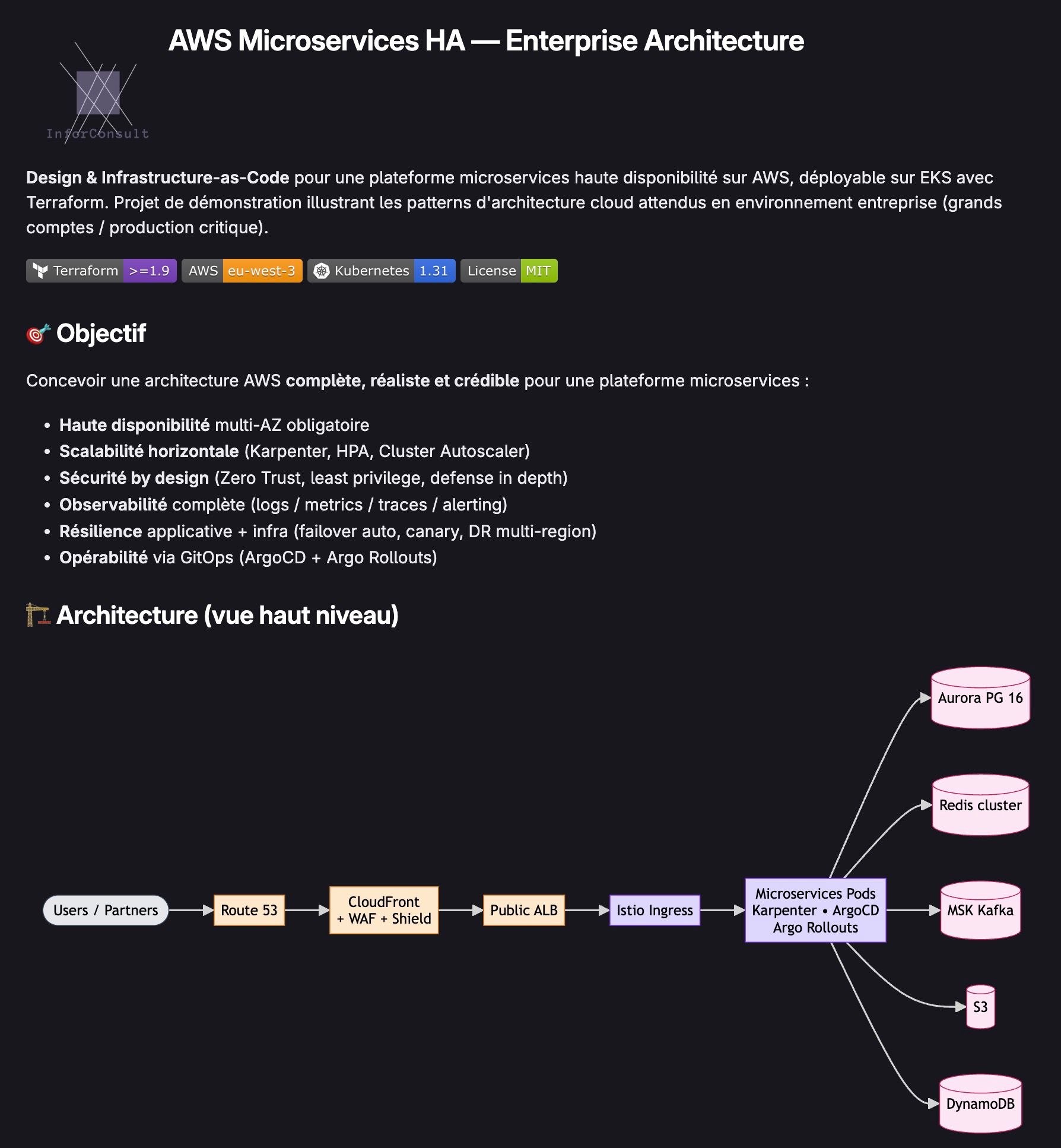
Le principe global est simple :
- Les utilisateurs arrivent via Internet
- Le trafic passe par une couche de protection et de distribution
- Il est ensuite dirigé vers des services applicatifs (microservices)
- Les données sont stockées dans plusieurs systèmes spécialisés
👉 L’objectif : éviter tout point de défaillance unique
Concrètement :
- plusieurs zones de disponibilité (data centers AWS)
- duplication des services
- bascule automatique en cas de problème
🌐 2. Un réseau conçu pour isoler et protéger
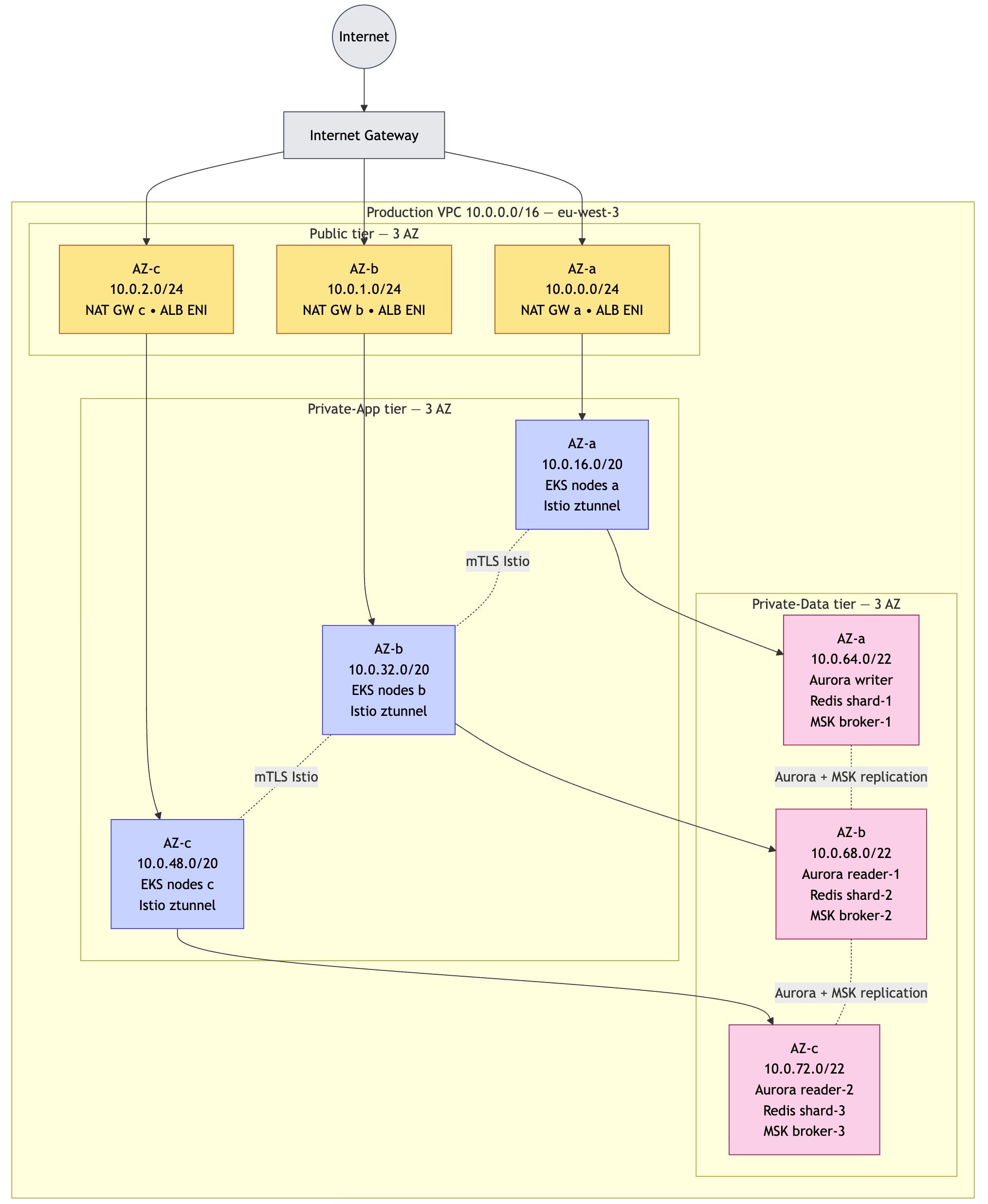
Le réseau est structuré en 3 niveaux :
- Public → exposé à Internet (entrée du trafic)
- Privé applicatif → les services métiers
- Privé data → les bases de données (ultra isolées)
👉 Résultat :
- les données sensibles ne sont jamais exposées
- chaque couche a des règles de sécurité spécifiques
💾 3. Des données réparties selon leur usage
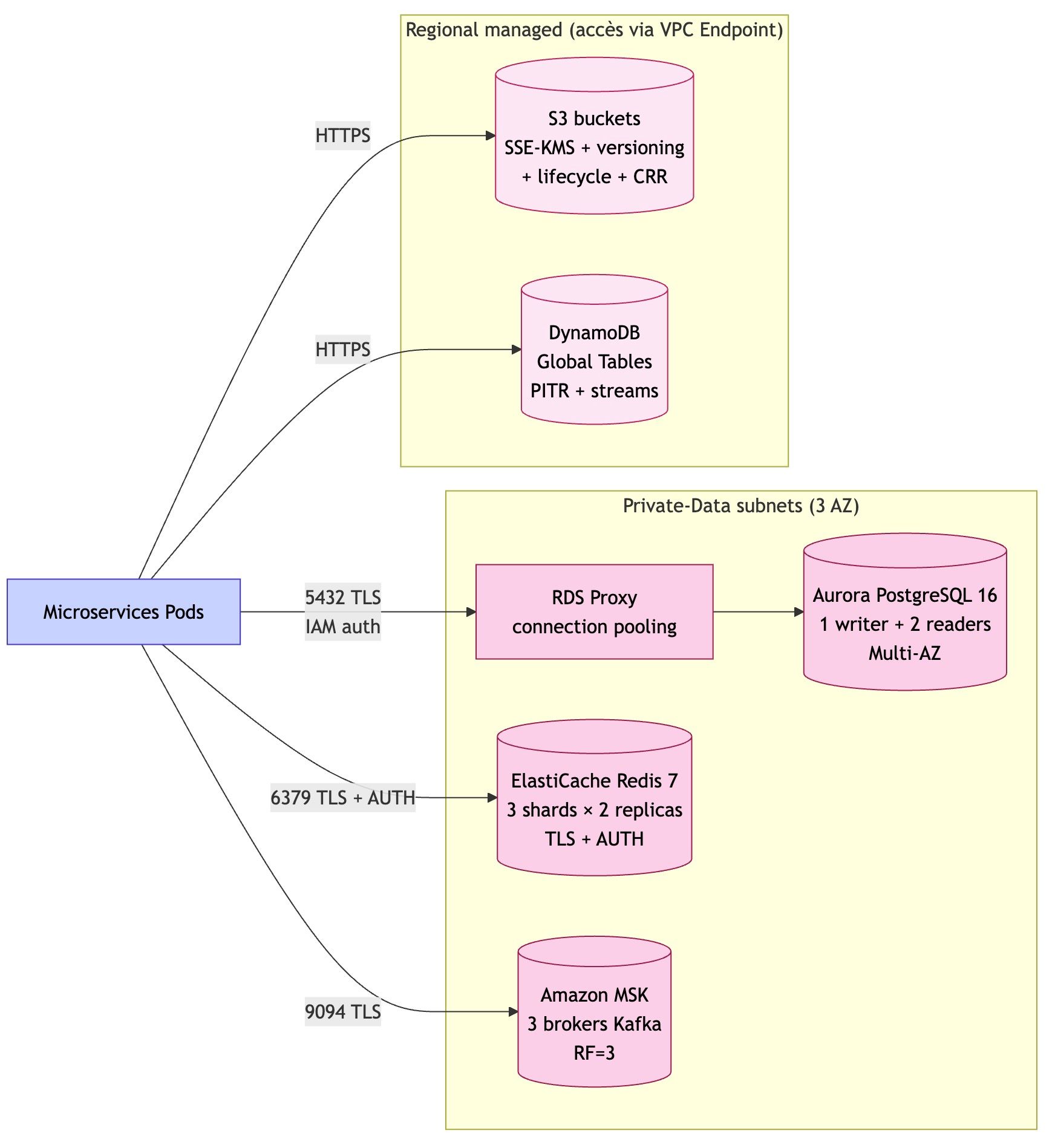
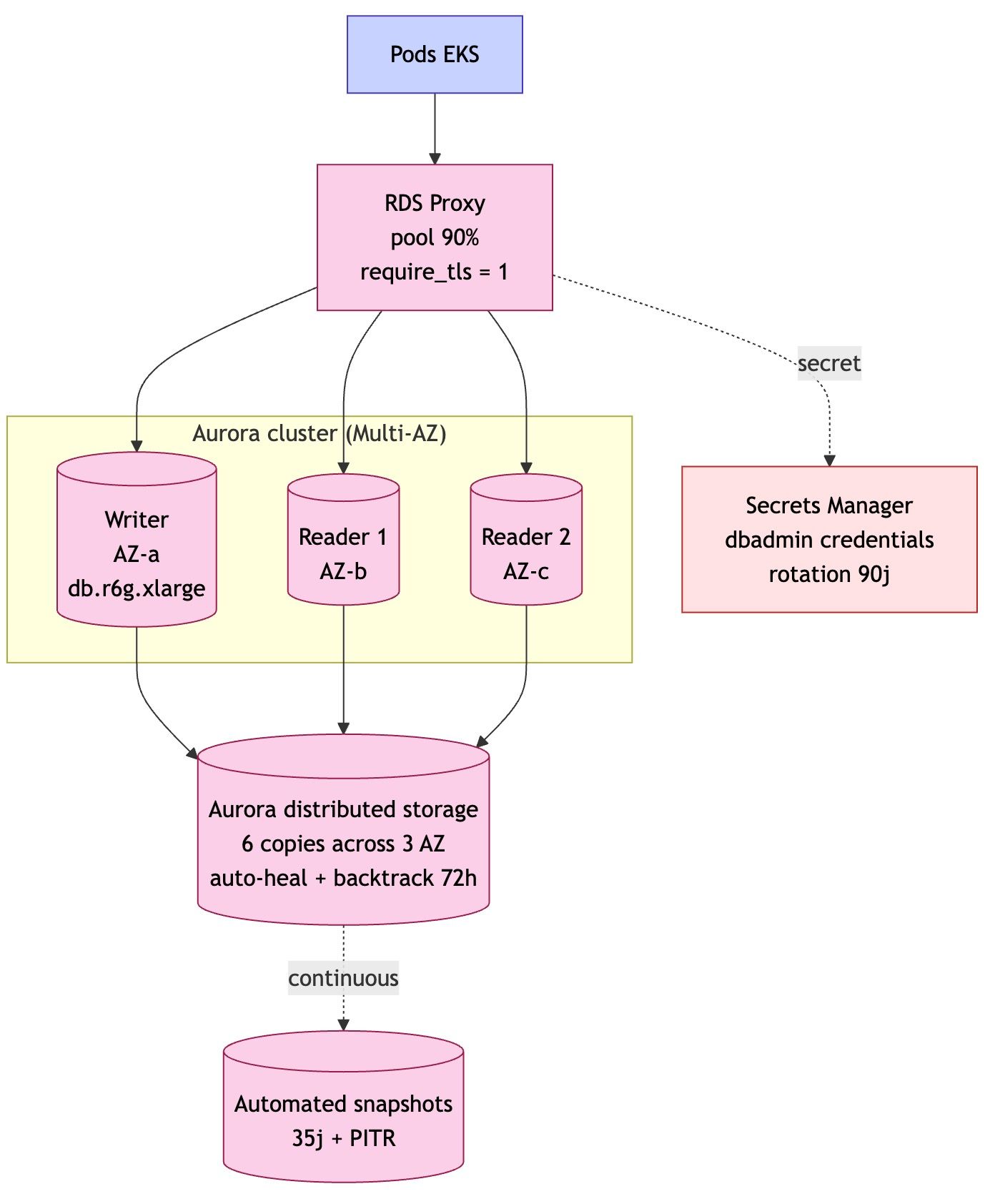
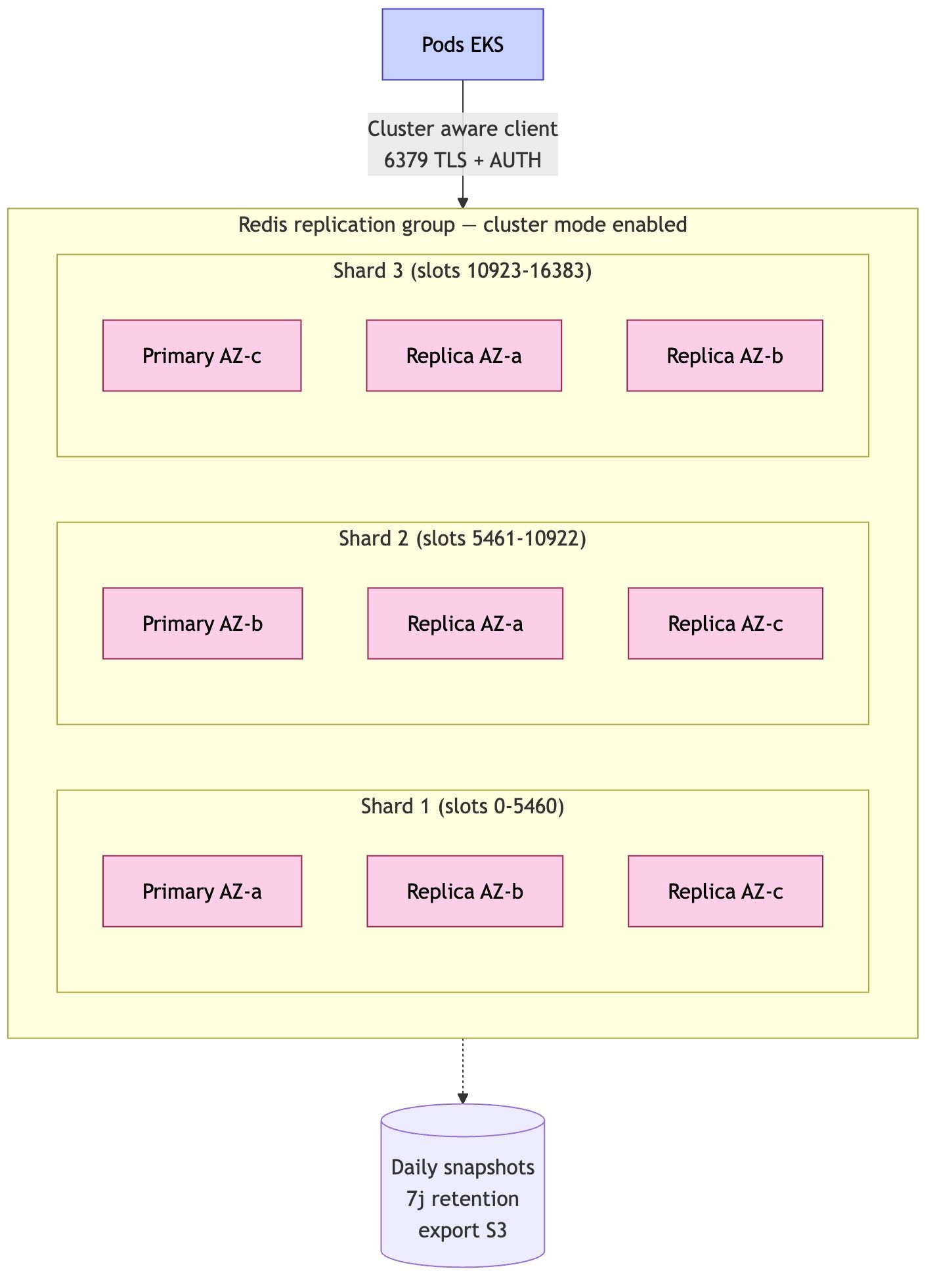
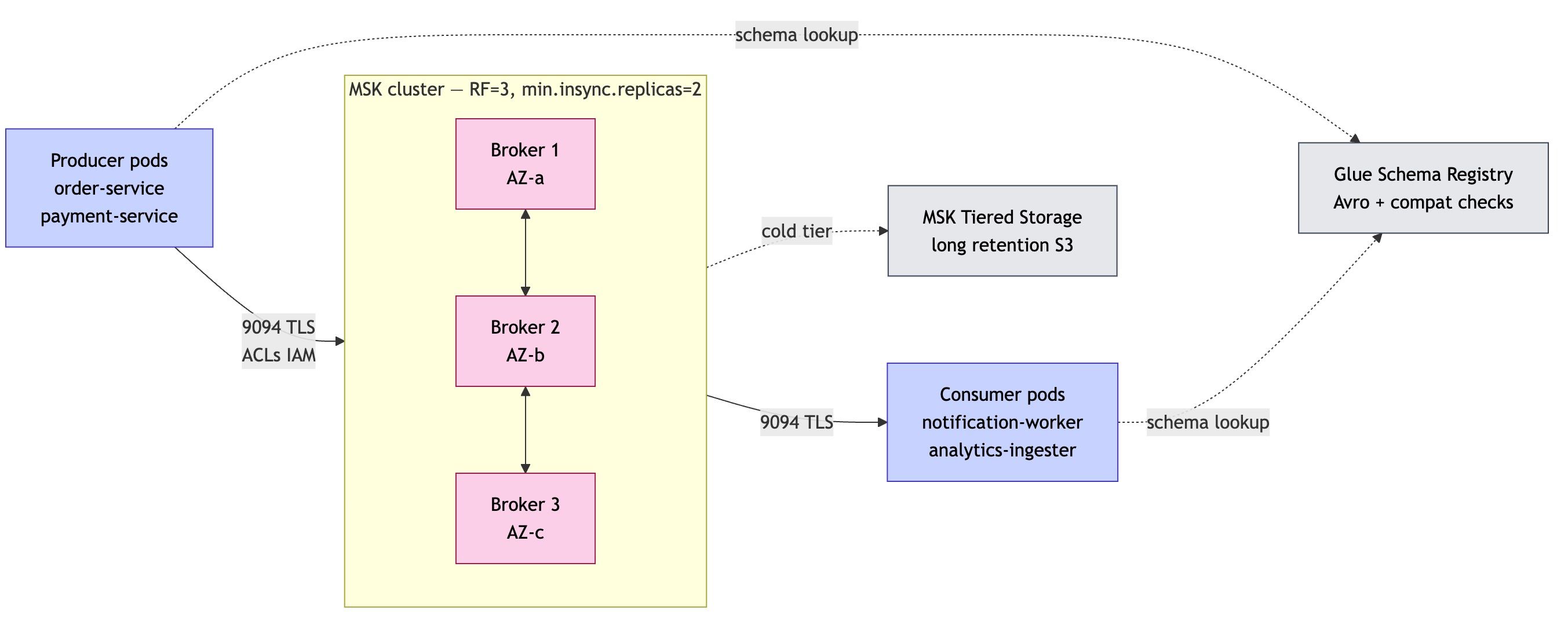
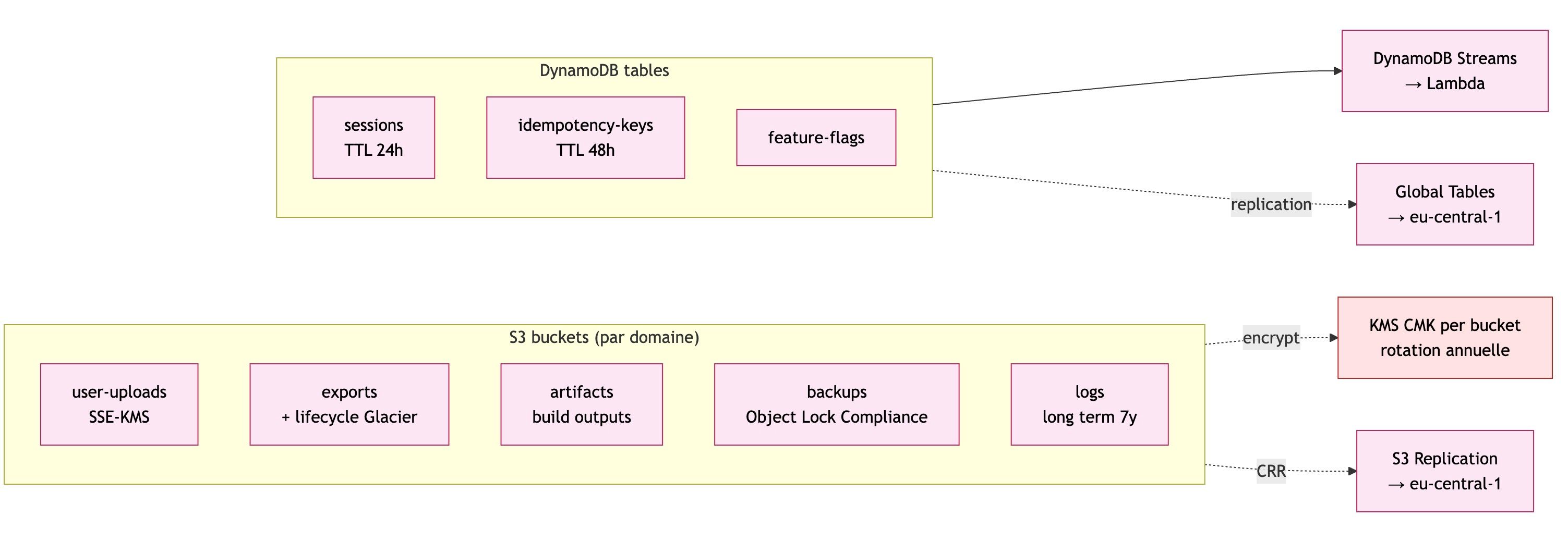
Toutes les données ne se ressemblent pas. Donc on utilise plusieurs technologies :
- Base relationnelle → pour les transactions (ex : commandes)
- Cache → pour la performance
- Streaming → pour les événements en temps réel
- Stockage objet → pour fichiers et sauvegardes
- Base clé-valeur → pour la vitesse extrême
👉 Objectif : performance + résilience + scalabilité
🚀 4. Des déploiements sans interruption (et sans stress)


Le déploiement suit un principe simple :
- Code testé automatiquement
- Analyse de sécurité
- Build et validation
- Déploiement progressif
👉 Exemple concret :
- on déploie une nouvelle version sur 5% des utilisateurs
- on observe le comportement
- si tout va bien → on augmente progressivement
👉 Sinon → rollback automatique
Résultat :
- moins de risques
- plus de confiance
- plus de vitesse
📊 5. Une visibilité complète (observabilité)
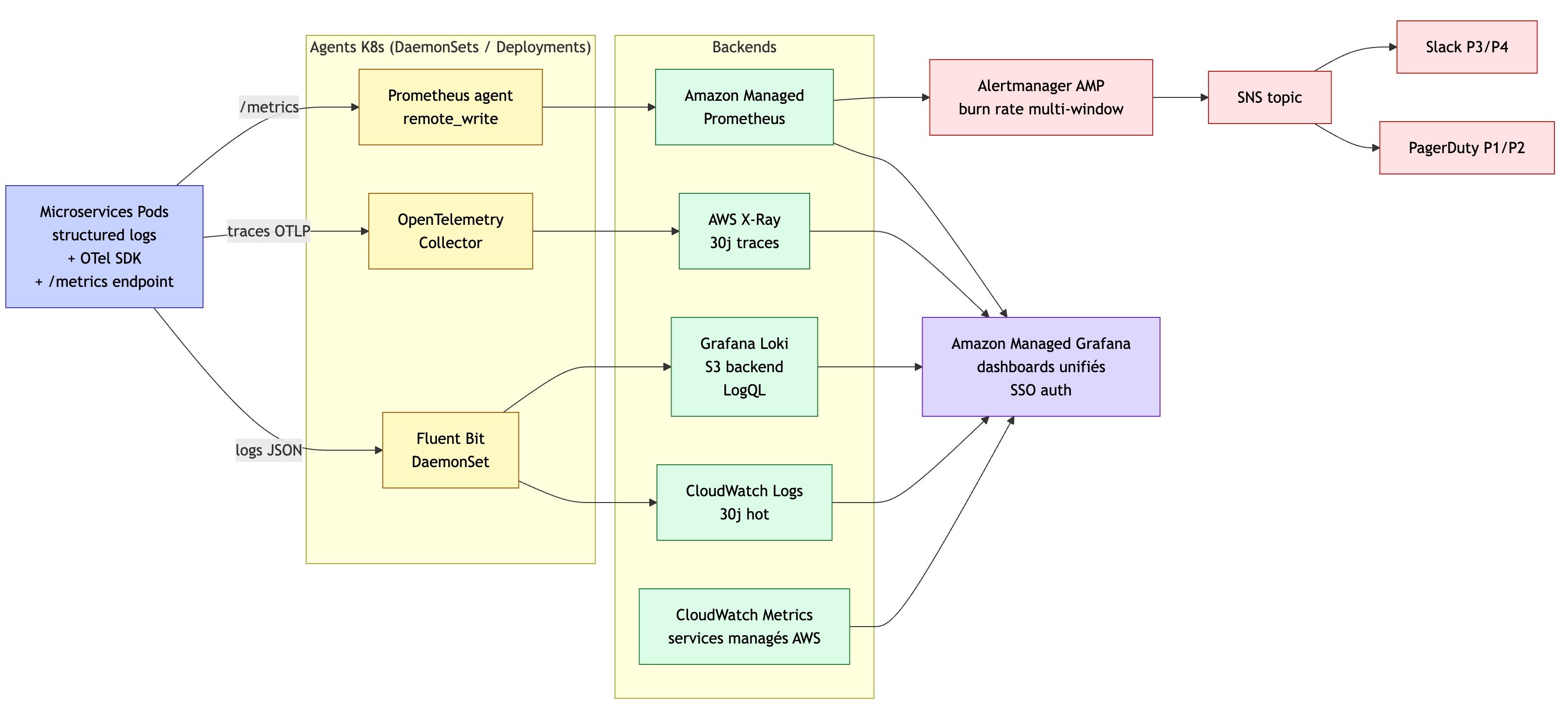
Une plateforme fiable, c’est une plateforme que l’on comprend.
On surveille donc :
- les logs (ce qui s’est passé)
- les métriques (CPU, erreurs, latence)
- les traces (parcours complet d’une requête)
👉 Et surtout : on ne déclenche pas d’alertes “bêtes”
On utilise des SLO (objectifs de service) : → alerter uniquement quand l’expérience utilisateur est réellement impactée
🔐 6. Une sécurité pensée dès le départ
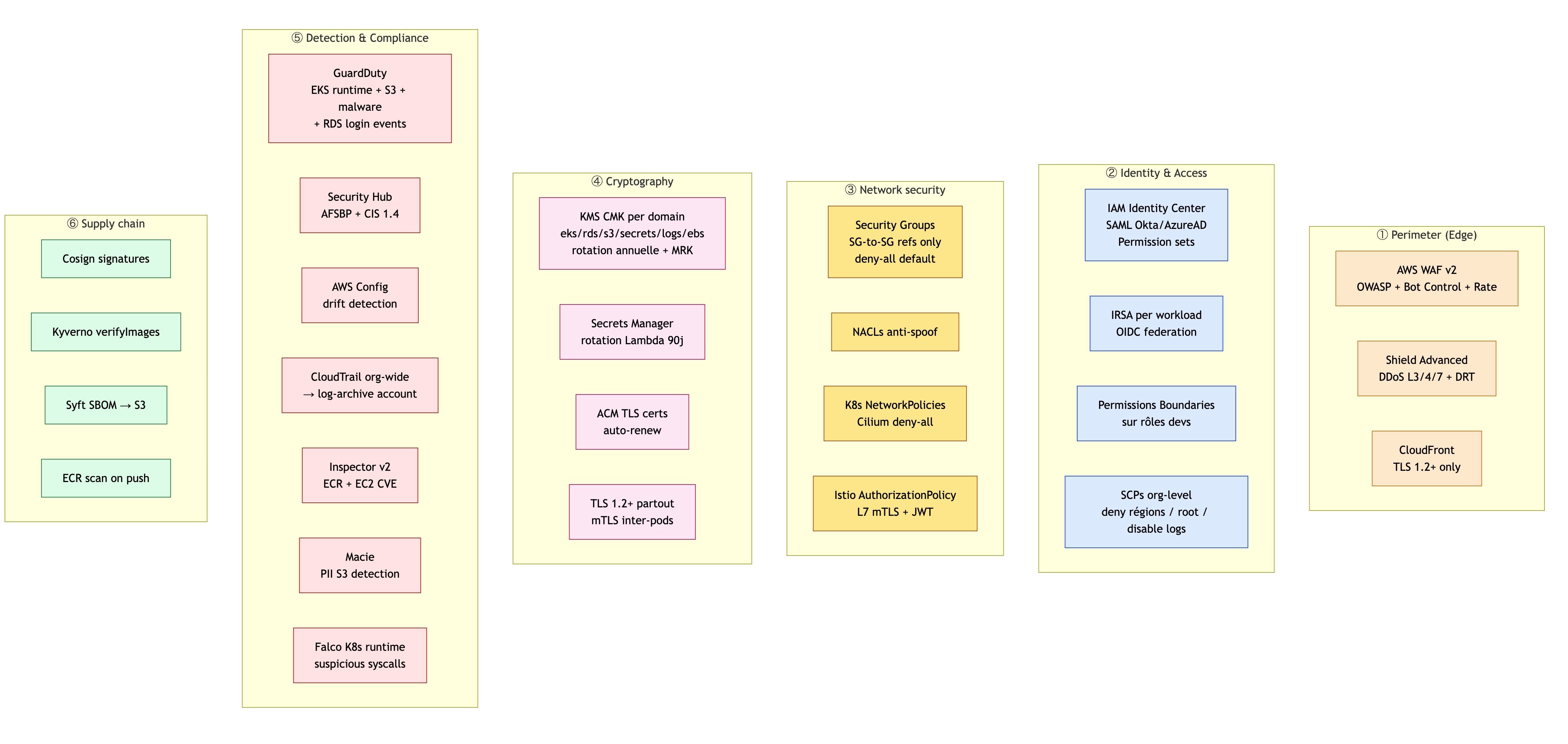
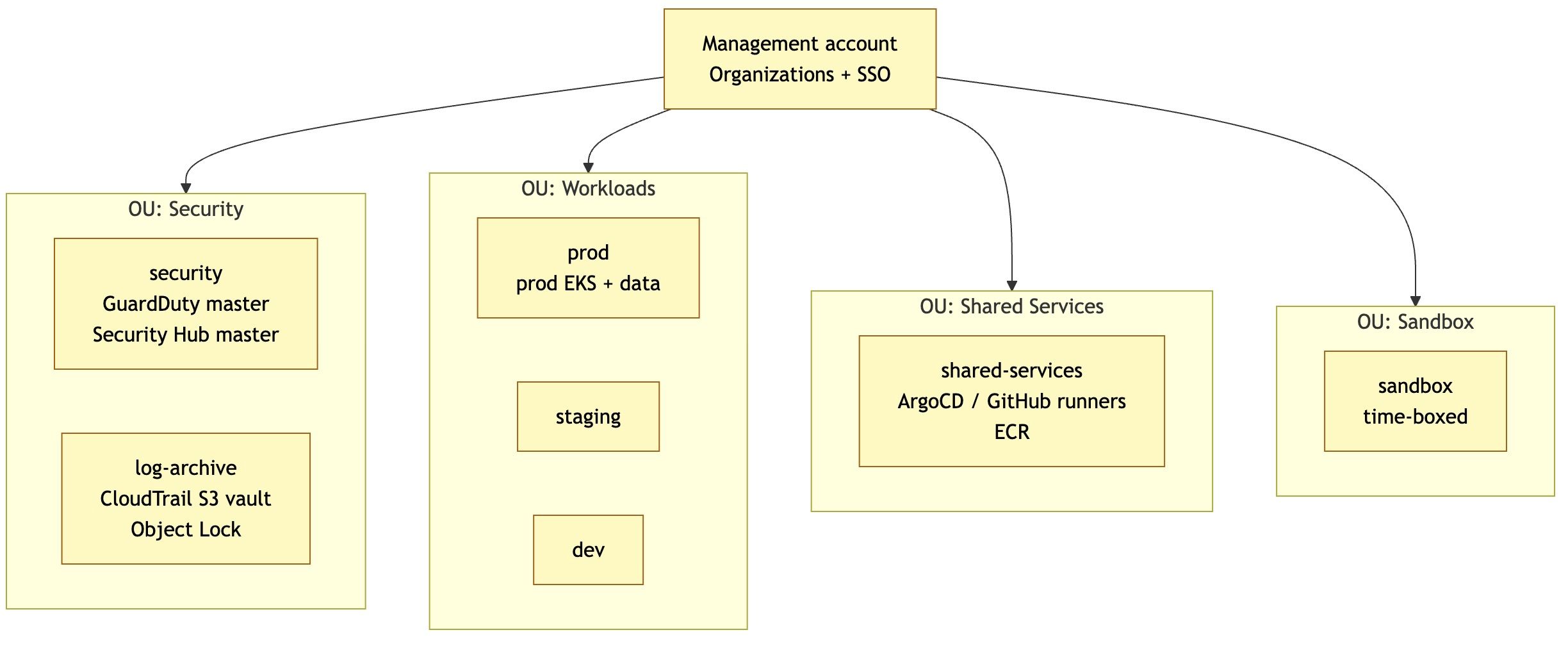
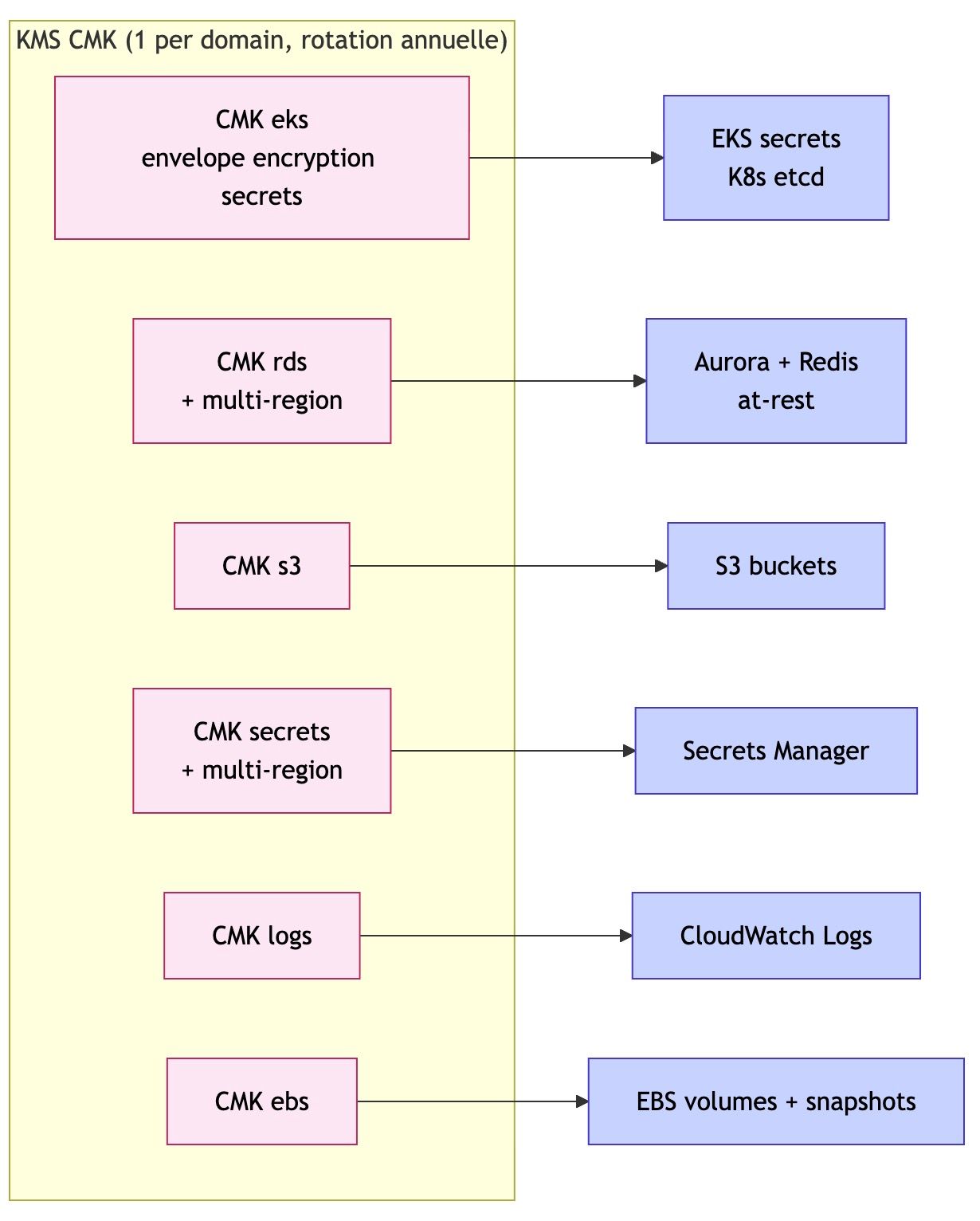
La sécurité repose sur plusieurs principes :
- Zero Trust → rien n’est autorisé par défaut
- Moindre privilège → chaque service a uniquement les droits nécessaires
- Chiffrement partout
- Aucune exposition inutile (pas de SSH, pas de bastion)
👉 Exemple : les accès humains passent par des systèmes sécurisés et audités → pas de “porte dérobée”
🔄 7. Et si toute la région tombe ?
C’est LA question que peu d’entreprises se posent vraiment.
Dans cette architecture :
- les données sont répliquées dans une autre région AWS
- une infrastructure minimale est déjà prête ailleurs
- un basculement peut être déclenché
👉 Objectif :
- perte de données quasi nulle
- reprise en ~30 minutes
🧭 Ce qu’il faut retenir
Une architecture cloud moderne, ce n’est pas juste : 👉 “mettre des serveurs dans le cloud”
C’est un ensemble cohérent de choix :
- disponibilité
- sécurité
- performance
- automatisation
- résilience
Et surtout : 👉 tout doit être pensé dès le départ
💡 Pourquoi ça intéresse les dirigeants ?
Parce que derrière la technique, il y a des enjeux business :
- éviter les interruptions de service
- protéger les données
- accélérer le time-to-market
- réduire les risques (cyber, opérationnels)
- garantir la continuité d’activité
🔚 Conclusion
Beaucoup d’entreprises pensent être protégées…
…jusqu’au jour où ça casse.
👉 Une architecture robuste ne s’improvise pas.
C’est exactement le type de réflexion que je mène dans mes missions : concevoir des systèmes fiables, testés, et réellement adaptés aux contraintes métier.
Si ces sujets vous parlent (architecture cloud, résilience, automatisation, IA appliquée aux opérations), je serais curieux d’échanger.