Ce que les pratiques SRE des grands comptes peuvent apprendre à n'importe quelle PME
⚙️ SRE, PRA, RTO, RPO... Des acronymes qu'on associe plutôt aux grandes infrastructures cloud. Et pourtant, les principes qui sont derrière sont exactement les mêmes qui devraient guider la résilience informatique d'une PME de 10 postes. On n'a pas besoin d'un cluster Kubernetes multi-région pour appliquer une logique de résilience sérieuse. On a juste besoin de se poser les bonnes questions — celles que les équipes SRE se posent tous les jours sur des systèmes critiques.
 SRE : une discipline née pour la haute disponibilité, utile bien au-delà
SRE : une discipline née pour la haute disponibilité, utile bien au-delà
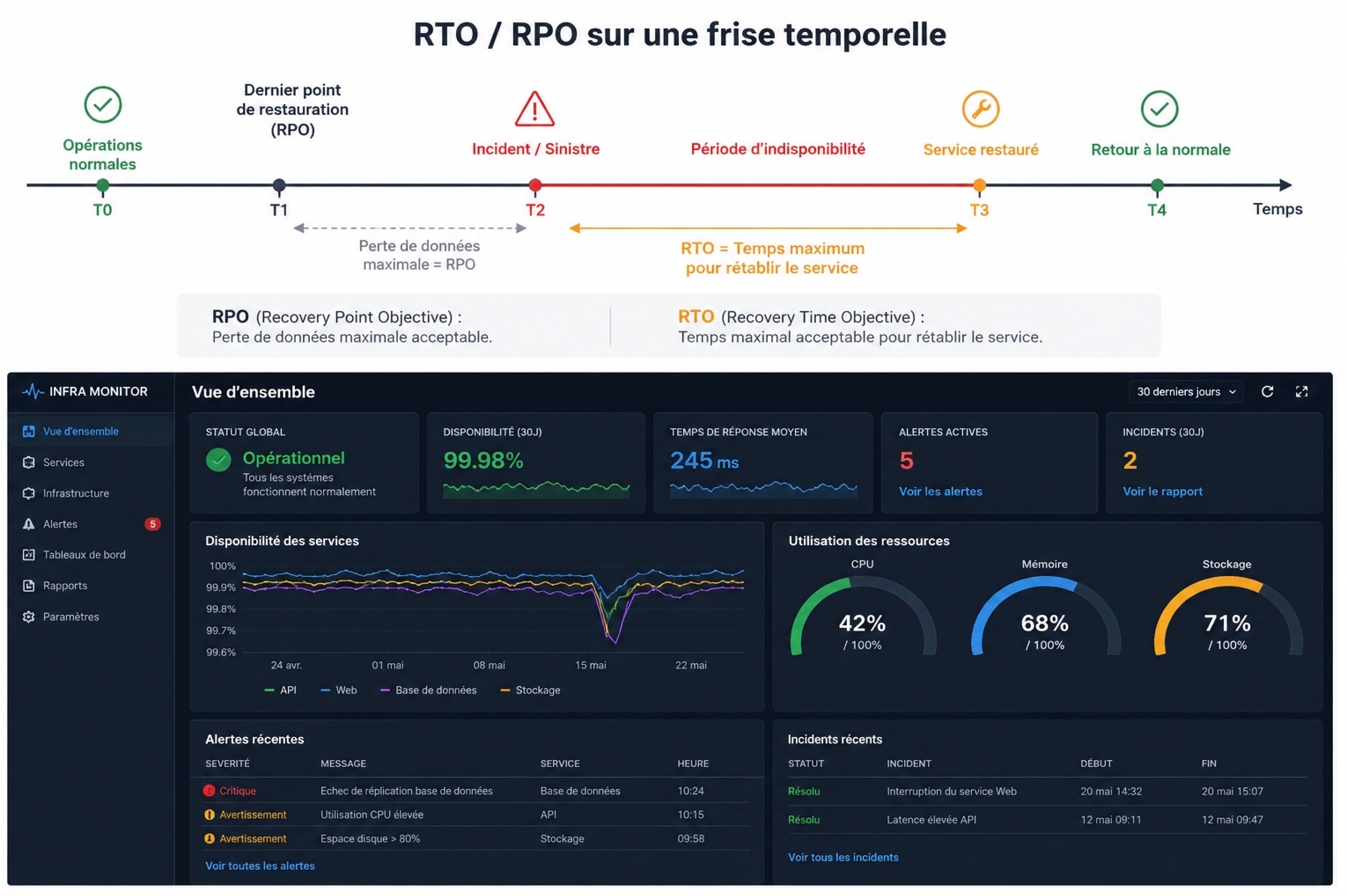
Le Site Reliability Engineering (SRE) est une discipline qui vise à garantir la fiabilité de systèmes complexes, en s'appuyant sur des objectifs mesurables plutôt que sur des impressions. Deux notions structurent cette approche : le RTO (Recovery Time Objective — combien de temps on accepte d'être arrêté) et le RPO (Recovery Point Objective — combien de données on accepte de perdre).
Ces deux questions ne sont pas réservées aux infrastructures cloud à grande échelle. Elles s'appliquent, avec le même bon sens, à un serveur de PME
Se poser la question du RTO avant la panne, pas pendant
Combien de temps une PME peut-elle tenir sans son serveur de facturation ? Une heure ? Une journée ? La réponse conditionne directement le niveau d'investissement à prévoir en matière de redondance et de plan de reprise. Beaucoup d'entreprises n'ont tout simplement jamais formulé cette réponse — et découvrent leur véritable tolérance au pire moment.
Se poser la question du RPO pour dimensionner la fréquence de sauvegarde
Le RPO détermine la fréquence de sauvegarde nécessaire. Perdre une heure de données n'a pas le même impact que perdre une journée. C'est ce paramètre, plus que la technologie choisie, qui doit piloter la stratégie de sauvegarde.
Le PRA : formaliser ce qui reste souvent implicite
Un Plan de Reprise d'Activité (PRA) documente noir sur blanc : qui fait quoi, dans quel ordre, avec quels accès, en cas d'incident majeur. Sur les grandes infrastructures, ce plan est testé régulièrement — chaos engineering, exercices de bascule planifiés. Sur les PME, il est souvent absent, ou resté dans la tête d'une seule personne. Le jour où cette personne est indisponible, l'entreprise découvre le vrai coût de l'absence de formalisation.
Une discipline transposable, à l'échelle d'une PME
Il ne s'agit pas de déployer les mêmes outils qu'un grand compte, mais d'appliquer la même rigueur : objectifs mesurables, tests réguliers, documentation à jour. C'est une bonne partie du travail mené en parallèle sur des infrastructures cloud critiques (Terraform, Kubernetes, AWS) qui vient nourrir la façon dont Inforconsult structure la résilience des systèmes d'information des PME accompagnées.