POC Enrichissement des alertes de supervision — De l'alerte brute au diagnostic augmenté par IA
🔧 Dans ce POC, j'ai choisi d'améliorer la gestion des alertes issues de mon infrastructure, actuellement supervisée via Grafana, Prometheus, Loki et Alertmanager pour la gestion des notifications email. ⚠️ Plusieurs limites sont rapidement apparues, tant sur le fond que sur la forme. En particulier, le format des emails était peu exploitable, et les informations transmises manquaient de clarté et de hiérarchisation. Un point problématique notable concernait la distinction entre une alerte active et une alerte résolue : dans les deux cas, l'email reçu était strictement identique, avec un titre "ALERTE" dans les deux cas, et avec un attribut "resolved" présent dans les détails, peu visible et facilement manqué. 📧 Dans un premier temps, j'ai donc retravaillé la présentation des notifications. Pour cela, j'ai modifié la configuration d'Alertmanager afin d'envoyer les événements vers un webhook, reçu ensuite dans un workflow n8n pour reformatage. Ce premier niveau d'amélioration a permis d'obtenir un gain immédiat en lisibilité et en ergonomie. 📊 L'étape suivante a consisté à enrichir le contenu des alertes en exploitant les données de Prometheus et de Loki. Concrètement, lors du déclenchement d'une alerte, le système interroge Loki puis Prometheus afin d'identifier des signaux corrélés. 🤖 Enfin, une couche d'analyse par IA a été intégrée via un LLM auto-hébergé (Ollama) pour compléter le diagnostic. Le modèle reçoit le contexte de l'alerte et propose une analyse en langage naturel avec des pistes de résolution adaptées. 🔍 Le résultat : chaque alerte est accompagnée de logs corrélés, de la valeur temps réel de la métrique, de commandes de remédiation prêtes à l'emploi, et d'un diagnostic IA contextuel. ✅ Ainsi, le message d'alerte ne se limite plus à un simple signal brut : il devient un point d'entrée directement exploitable pour le diagnostic et la remédiation.
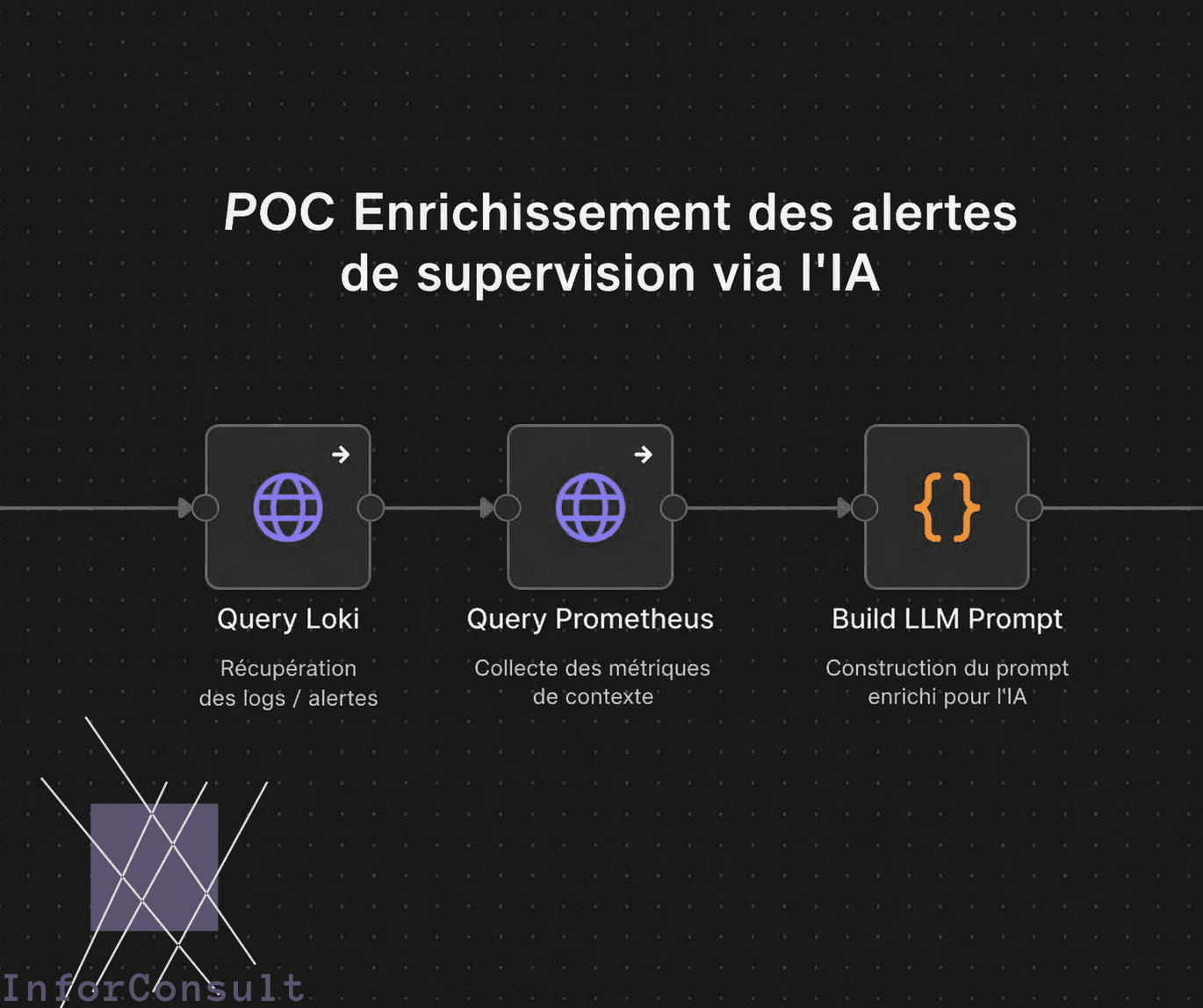
Architecture technique du POC
- Prometheus (LAN) : collecte les métriques système via node_exporter sur l'ensemble du parc (CPU, RAM, disque, réseau, SMART).
- Grafana (LAN) : visualisation, dashboards et gestion des alertes.
- Loki (LAN) : agrégation centralisée des logs via Promtail, indexés par labels (instance, job, level, log_type, service_name, filename).
- Alertmanager (LAN) : réception des alertes Prometheus, déduplication, routage vers le webhook n8n.
- Ollama (LAN) : serveur LLM auto-hébergé exécutant un modèle léger, dédié à l'analyse des alertes.
- n8n (DMZ) : orchestration du workflow d'enrichissement, appel au LLM et envoi des emails.

18 règles d'alerte Prometheus sont définies, organisées en fichiers thématiques couvrant les métriques système (CPU, mémoire, disque, filesystem), les services applicatifs, les sondes blackbox, le réseau et la santé SMART des disques. Ce sont les règles du groupe node (CPUHigh, MemHigh, FSDanger, FilesystemReadOnly) qui bénéficient directement de l'enrichissement dans ce POC.
Test 1 : Arrêt manuel d'un node.
Email d'alerte avant retraitement :
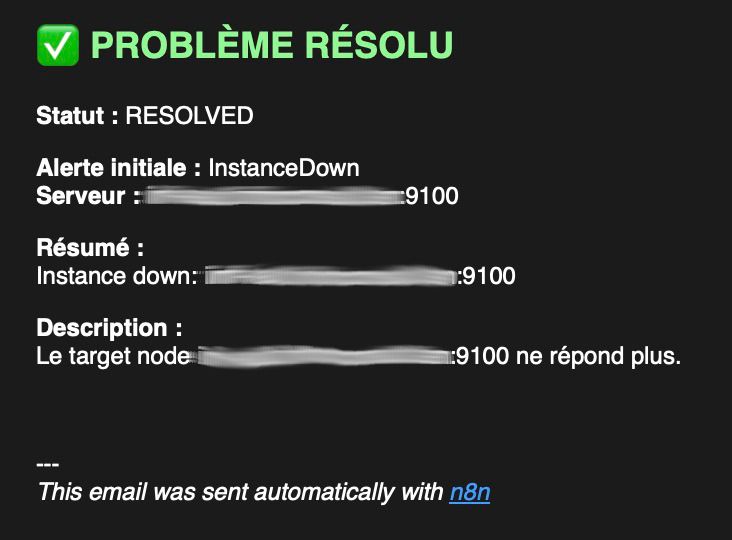
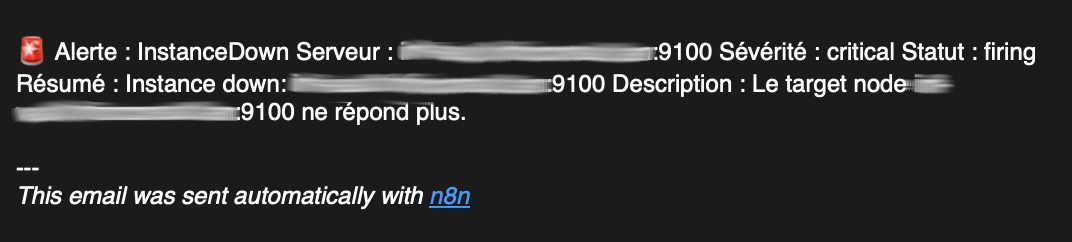 Email de résolution avant retraitement :
Email de résolution avant retraitement :
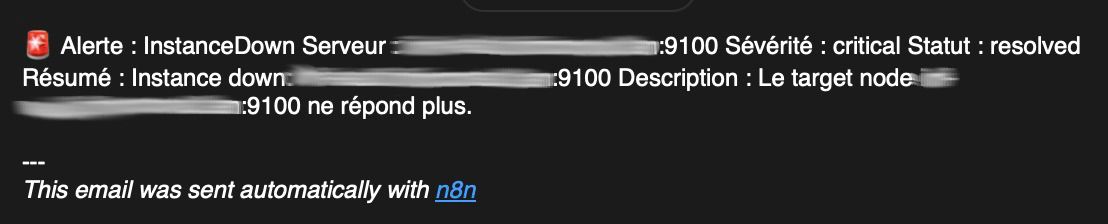
Pas très clair...
Un workflow n8n initial a donc été mis en place pour intercepter les événements via webhook et reconstruire entièrement l'email. Le code JavaScript en entrée du workflow parse le payload Alertmanager, extrait les champs utiles (nom de l'alerte, instance, sévérité, durée du downtime) et les transmet à un nœud de mise en forme HTML. Ce dernier génère un email structuré avec un code couleur immédiatement lisible : rouge pour une alerte active, vert pour une résolution, avec un sujet d'email conditionnel permettant le tri en boîte de réception d'un simple coup d'œil. Ce premier palier, relativement simple à mettre en œuvre, a suffi à transformer l'expérience utilisateur côté notification.
Mail d'alerte
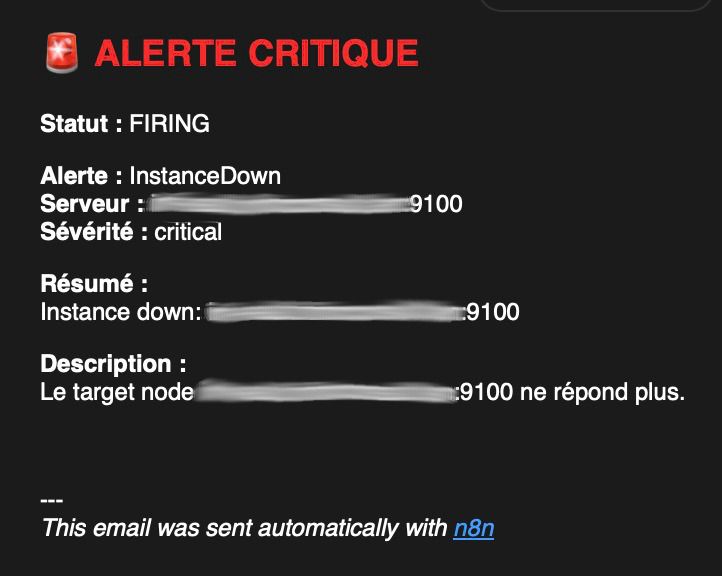
Mail de résolution
C'est sur cette base que s'appuient les étapes suivantes.
Workflow n8n : de l'alerte brute au diagnostic enrichi
Chaîne de traitement initiale
Le workflow recevait les alertes Alertmanager via webhook POST, extrayait les champs clés (alertname, instance, severity, status, durée), formatait un email HTML et l'envoyait. Fonctionnel, mais limité : aucun contexte, aucune aide au diagnostic.
Chaîne enrichie
Cinq nœuds ont été insérés entre le parsing de l'alerte et la mise en forme de l'email :
- Build Queries (Code JavaScript) — Construit dynamiquement les requêtes Loki et Prometheus selon le type d'alerte. Par exemple, pour une alerte CPUHigh, la requête Prometheus calculera le pourcentage CPU réel via
rate(node_cpu_seconds_total); pour FSDanger, elle cartographiera l'occupation de chaque point de montage. Un point d'attention a été la corrélation des labels entre Prometheus (FQDN avec port) et Loki (hostname court) : le nœud extrait automatiquement le hostname court pour interroger Loki. - Query Loki (HTTP Request) — Interroge l'API Loki sur une fenêtre de 15 minutes en filtrant les logs de l'instance concernée avec un pattern regex ciblant les niveaux error, critical, warn, fail, panic, oom et killed. Le label
instancesert de clé de corrélation entre l'alerte Prometheus et les logs Loki. - Query Prometheus (HTTP Request) — Récupère la valeur en temps réel de la métrique en alerte. Le technicien voit immédiatement si le problème est toujours actif au moment de la lecture de l'email.
- Build LLM Prompt (Code JavaScript) — Prépare le contexte pour le LLM : type d'alerte, instance concernée, sévérité et valeur actuelle de la métrique. Le prompt est volontairement concis pour garantir un temps de réponse acceptable. Ce nœud isole la construction de la requête de l'appel HTTP, ce qui s'est avéré nécessaire pour contourner les limitations du parser d'expressions n8n sur les payloads JSON complexes.
- LLM Diagnostic (HTTP Request) — Envoie le prompt au serveur Ollama et récupère la réponse. Le modèle retourne un diagnostic en langage naturel avec des actions correctives adaptées au type d'incident.
- Analyse et Suggestions (Code JavaScript) — Compile l'ensemble des données (Loki, Prometheus, LLM) et génère :
- Un niveau de criticité calculé dynamiquement (pas seulement la severity de l'alerte, mais aussi le volume de logs d'erreur détectés).
- La valeur temps réel de la métrique (ex : « 87.3% CPU »).
- Des commandes de remédiation directement exécutables, adaptées au type d'incident, générées par règles déterministes (switch/case selon le type d'alerte). Par exemple, pour un disque plein : identification des répertoires volumineux, purge des anciens logs journald, nettoyage des paquets obsolètes.
- Le diagnostic IA en langage naturel, présenté dans une section dédiée de l'email.
L'email final intègre désormais un tableau de synthèse, les dernières lignes de logs Loki pertinentes, une liste de commandes prêtes à l'emploi, et le diagnostic IA. La distinction visuelle entre alerte active et résolue est appliquée dès le sujet de l'email — les emails de résolution ne contiennent volontairement que le résumé, sans le bloc d'analyse complet.
Test 2 : stress-test CPU d'un node
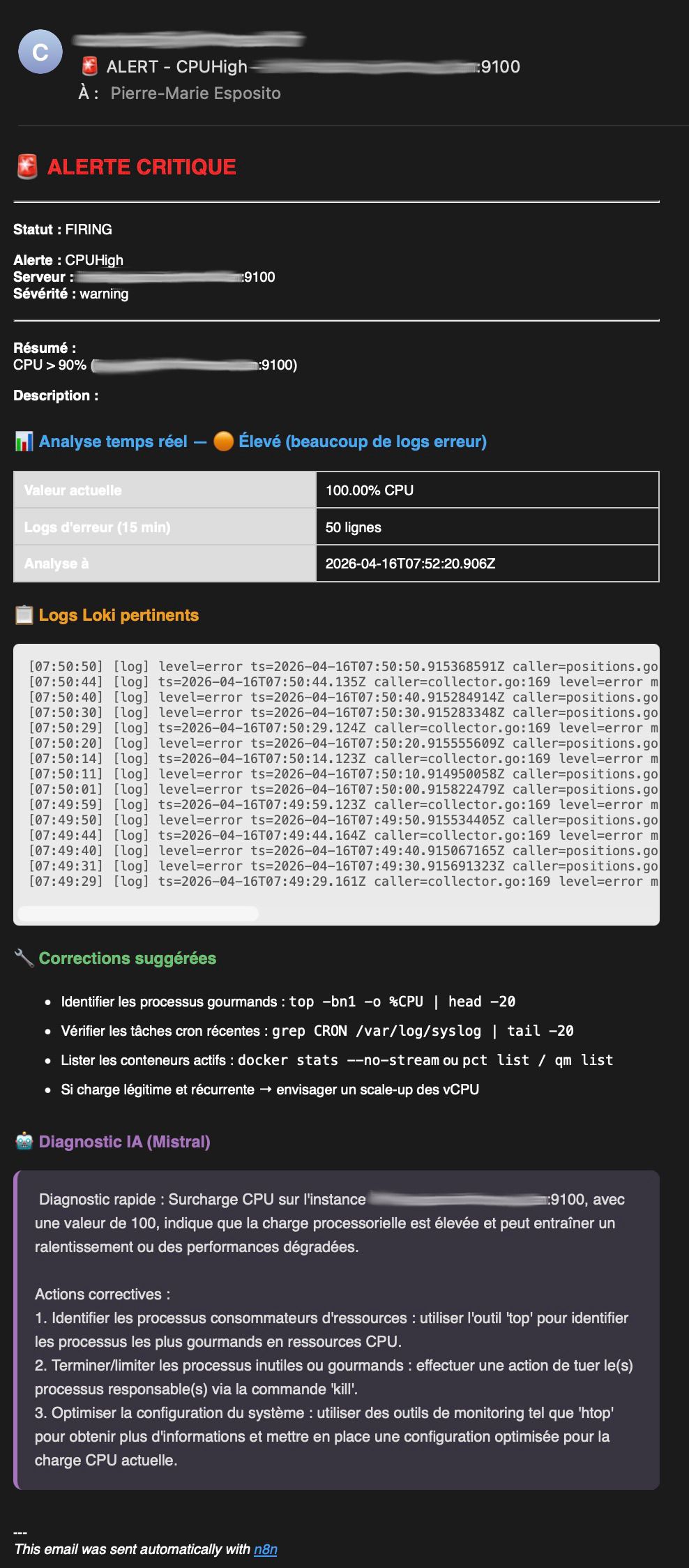
Email d'alerte enrichie par l'IA
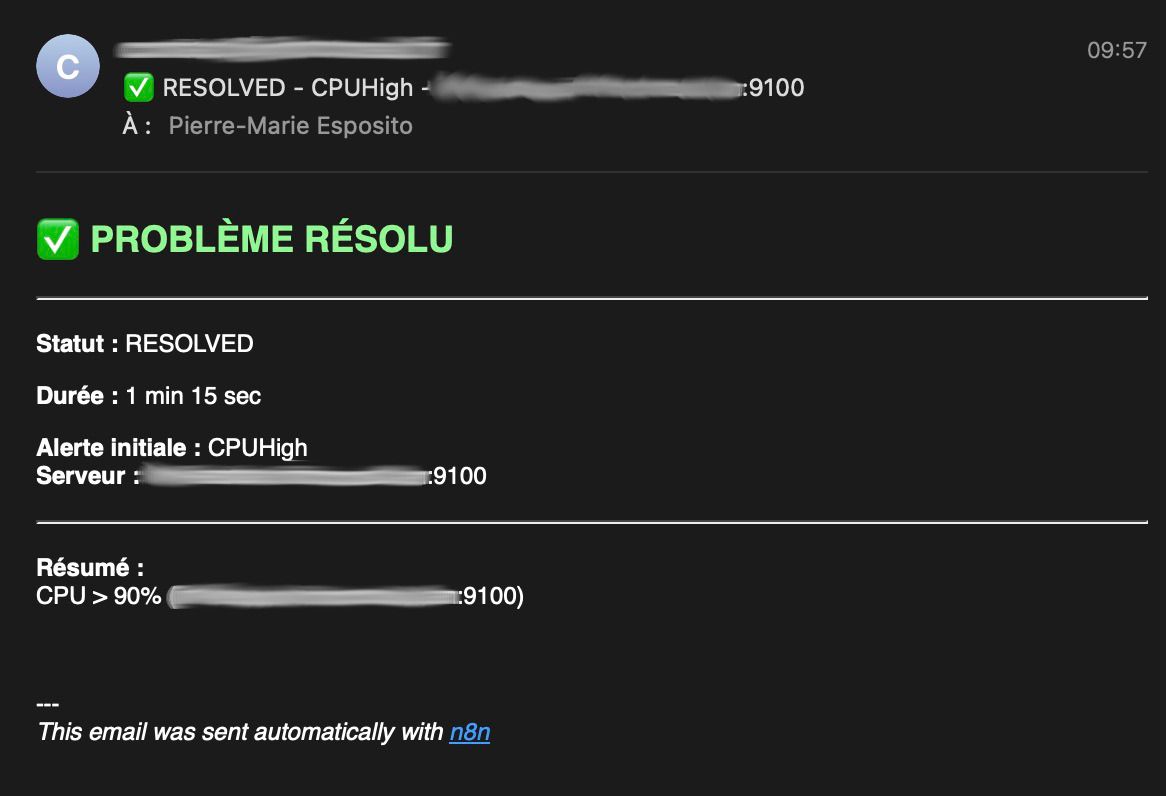
Email de résolution avec MTTR
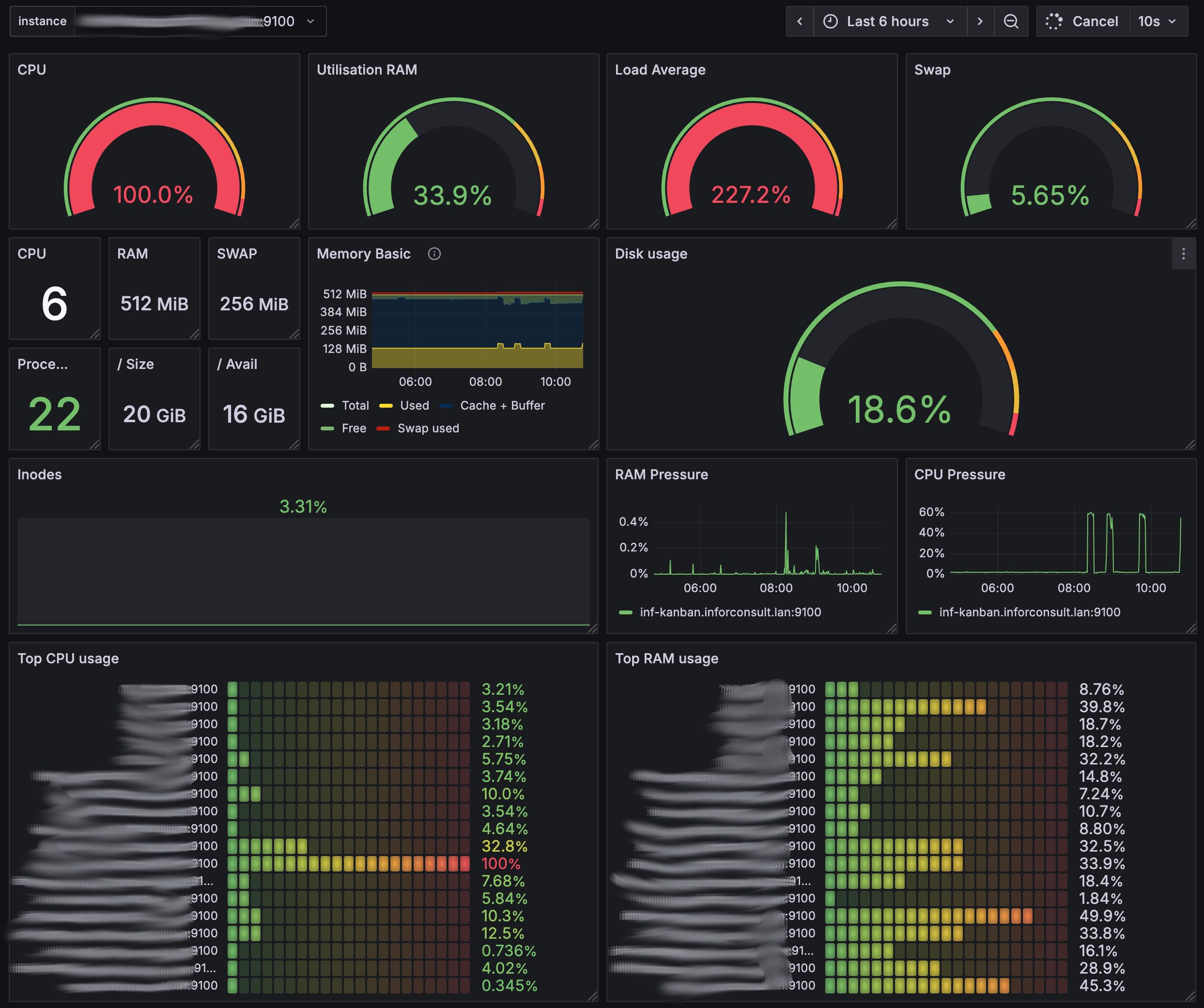
Déclenchement de l'alerte pour le test Pour valider la chaîne complète, le déclenchement de l'alerte a été provoqué par un stress-test CPU volontaire sur un conteneur de test. Ce type de sollicitation manuelle permet de vérifier le bon fonctionnement de bout en bout — du déclenchement Prometheus à la réception de l'email enrichi — sans attendre un incident réel. Le mail reçu montre d'ailleurs une valeur CPU à 100%, cohérente avec la charge artificielle injectée.
 Intégration du LLM : choix et contraintes
Intégration du LLM : choix et contraintes
Le choix d'un LLM auto-hébergé plutôt qu'une API cloud s'est imposé pour des raisons de souveraineté des données (les alertes contiennent des informations d'infrastructure interne) et de maîtrise des coûts. Ollama a été retenu pour sa simplicité de déploiement et son support natif de plusieurs modèles open source.
Le dimensionnement a nécessité quelques itérations. Un modèle 7B de paramètres, bien que plus précis dans ses analyses, s'est avéré trop lent en inférence CPU pure (30 secondes pour une phrase simple, plusieurs minutes pour un prompt de diagnostic complet). Le passage à un modèle plus léger (3.8B paramètres) a ramené le temps de réponse à quelques secondes, avec une qualité de diagnostic tout à fait exploitable pour ce cas d'usage. La différence de pertinence se manifesterait surtout sur des corrélations complexes entre logs — ce qui n'est pas le besoin principal ici, puisque les suggestions déterministes couvrent déjà les actions de remédiation classiques.
Le modèle LLM (phi3:mini) tourne sur une lxc sans GPU Nvidia, avec 16G de Ram 8vcpu et 40G de disque. Serveur proxmox : Intel Xeon-D 2141I - 8c/16t - 2.2 GHz/3 GHz / 64 Go ECC 2133 MHz / PVE8
Bénéfices pour les équipes techniques
Même si l'analyse reste à affiner — notamment sur la pertinence des requêtes Loki selon les types d'incidents et la profondeur des diagnostics IA — le gain est déjà perceptible. Les logs corrélés et la valeur temps réel réduisent la phase initiale d'investigation manuelle. Le technicien dispose de commandes de remédiation directement exploitables depuis l'email. Le diagnostic IA ajoute une couche d'interprétation en langage naturel qui peut aider un profil moins expérimenté à comprendre la situation. Le niveau de criticité calculé automatiquement (intégrant le volume de logs d'erreur) offre une meilleure priorisation que la severity statique de l'alerte. La fenêtre de 15 minutes montre ce qui s'est passé juste avant le déclenchement — souvent plus révélateur que l'alerte elle-même. La chaîne est fonctionnelle de bout en bout ; il s'agit maintenant de l'enrichir itérativement pour gagner en précision.
Bénéfices pour les décideurs
Au-delà de l'aspect technique, ce POC démontre plusieurs points à valeur business. Le MTTR (Mean Time To Resolve) devrait diminuer quand le diagnostic arrive avec l'alerte, même si ce gain reste à mesurer sur la durée. Les suggestions de remédiation — qu'elles soient déterministes ou générées par le LLM — codifient le savoir-faire de l'équipe : même un junior ou un prestataire reçoit les bonnes pistes sans dépendre d'un expert disponible. L'ensemble repose sur des briques open source (Grafana, Prometheus, Loki, n8n, Ollama) — le surcoût est uniquement du temps d'intégration, pas de licences.
Perspectives
Ce POC constitue une base fonctionnelle. Les évolutions envisagées : l'enrichissement du prompt LLM avec des extraits de logs Loki (actuellement le modèle reçoit uniquement le type d'alerte et la valeur métrique, les logs étant présents dans l'email mais pas transmis au LLM pour des raisons de performance en inférence CPU), l'intégration de l'historique des commandes récentes (via l'audit log ou le journal systemd) afin de corréler une alerte avec une action humaine — par exemple identifier qu'un pic CPU fait suite à un stress-test volontaire ou qu'un reboot a été déclenché manuellement, ce qui changerait radicalement le diagnostic à produire. D'autres pistes incluent l'extension aux alertes applicatives via les labels Loki dédiés aux services, une escalade intelligente vers un canal de communication d'équipe ou un runbook automatisé en cas de pattern critique détecté (OOM killer, I/O errors), un feedback loop permettant aux techniciens de valider ou corriger les diagnostics pour améliorer les suggestions futures, et le passage éventuel à un modèle plus puissant si les ressources le permettent (GPU dédié ou modèle quantifié).
Pierre-Marie Esposito